コンポーネント開発者ガイド
コンポーネント開発について
JDK・クラスパス
コンポーネントとは
コンポーネントの種類
コンポーネントの構成要素
入力コネクタセット
出力コネクタセット
ストリームファクトリ
コンポーネントのクラス図
Componentクラス
executeメソッドとexecuteLoopメソッド
executeメソッド
executeLoopメソッド
コンポーネントのインスタンス
その他のメソッド
initメソッド
termメソッド
endFlowメソッド
cancelメソッド
ExecuteContext
ログ出力について
フローのログのカテゴリ
変数の取得
共有オブジェクトの引き回し
プロジェクトオーナーと実行ユーザー
セッション
コネクション
トランザクション
サンプル - 何もしないコンポーネント
プロパティ
プロパティのクラス構成
ValueProperty
CategoryProperty
ConnectionProperty
サンプル - プロパティ定義の例
ストリーム
入力ストリームの取得
ストリームのデータアクセス
Recordの使用
入力ストリームでのコンテナの扱い
ストリームプロパティとStreamFactory
Binaryストリーム
Textストリーム
HTMLストリーム
MIMEストリーム
CSVストリーム
FixedLengthストリーム
XMLストリーム
Recordストリーム
ParameterListストリーム
出力ストリームでのコンテナの扱い
ストリーム変数
streamPassThroughとStreamFactory
フィールド定義を固定する
入力ストリームを定義するコンポーネント
ループするコンポーネントの作成
サンプル - LoopStartコンポーネント
定義ファイル
分岐コンポーネントの作成
サンプル - 実行回数によって分岐するコンポーネント
入出力が複数あるコンポーネントの作成
定義ファイル
動的に入出力が増減するコンポーネント
エラー処理の設計
FlowException
State
メッセージリソース
FlowExceptionのその他の属性
トランザクション
拡張トランザクション
トランザクションマネージャー
トランザクションの実装
リカバリー処理の実装
標準コンポーネントでのトランザクションの実装例
コネクションの使用
サンプル - テーブル情報取得コンポーネント
汎用コネクションの使用
pluginCallの使用
IndependentMapの使用
リクエスト終了時のクリーンアップ
キャンセル処理の実装
実行エンジンに対する処理中の通知
cancelメソッドの実装
サーバー起動時の初期化とシャットダウン時の処理
コンポーネント初期化時のコールバック
サーバー終了時のコールバック
ライセンスチェック
ComponentCompilerの拡張
Component#cloneメソッドのオーバーライド
サンプル - 同時実行数制御コンポーネント
ComponentInvoker
その他のサンプル
フローサービスでは独自のコンポーネントをJavaで開発し追加することが可能になっています。
Componentクラスが実際にサーバー上で動作する機能そのものになります。
これ以外にもデザイナーのプラグインを作成することでUIの拡張を行うこともできますが、ここではサーバー側のComponentクラスのソースコードの書き方を中心に説明します。定義ファイルリファレンス を、
jarファイルの作成とそのインストールに関してはツールガイド を参照してください。
コンポーネントの開発はJDK8.0以降の環境で行ってください。
ascore-1610.0200.jar
asdesigner-1610.0200.jar
※ascore-1610.0200.jarと asdesigner-1610.0200.jarの「-1610.0200」の部分はインストールしたバージョンにより異なります。
作成するコンポーネントの内容によってはさらに別のjarファイルがコンパイル/実行に必要になる場合があります。
//showlibコマンドによって指定のクラスがどのjarに含まれているかが表示されます。
>showlib com.infoteria.asteria.flowlibrary2.stream.StreamDataXML
jar:file:C:\Program Files\asteria5\server\lib\ascore-1610.0200.jar!/com/infoteria/asteria/flowlibrary2/stream/StreamDataXML.class
必要に応じてここで表示されたjarファイルにもクラスパスを通してください。
フローサービスの中での役割から言えばコンポーネントとはフローにおける処理の単位です。
ファイルを読み込む
RDBからデータを取得する
メールを送信する
データを変換する
およそコンピュータ上で実現可能な処理はすべてフローサービスのコンポーネントとして実装することが可能です。
実装面から言えばコンポーネントとは「com.infoteria.asteria.flowengine2.flow.Component」のサブクラスのことです。
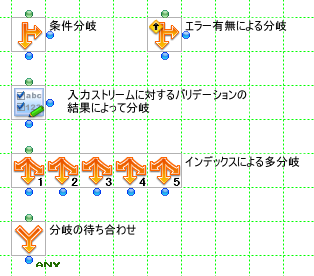
実装の観点からコンポーネントを考えた場合、以下のように分類することができます。
開始コンポーネント
終了コンポーネント
シンプルコンポーネント
分岐コンポーネント
複数入出力コンポーネント
SDKでは開始コンポーネント、終了コンポーネント以外のコンポーネントを作成することができます。
コンポーネント開発ではComponent クラスを継承し機能を拡張していくことになります。Component を継承した抽象クラスであるSimpleComponent クラスを継承して開発します。)
コンポーネント内部では様々なクラスが使用されていますが、ここでは先の分類に対応する形でコンポーネントを構成する主要クラスについて説明します。
入力コネクタセットは入力ストリームの受け口です。
開始コンポーネント以外のコンポーネントは必ずひとつの入力コネクタセットを持ちます。
上記の分類に沿って考えればサブコネクタをひとつも持たないコンポーネントがシンプルコンポーネントであり、
サブコネクタを持つコンポーネントが複数入力のあるコンポーネントです。
通常、入力コネクタにはひとつのリンクのみ接続可能ですが、Velocityコンポーネント のように複数のリンクを接続できる(= 複数の入力ストリームを扱える)ようにすることもできます。
コンポーネントは入力コネクタにストリームがセットされてはじめて実行可能な状態になるので、コンポーネント実行時には少なくとも一つ以上の
ストリームがデフォルトコネクタにセットされています。
出力コネクタはストリームの出口です。
出力コネクタセットは入力コネクタセットと同様にひとつのデフォルトコネクタと0個以上のサブコネクタを持ちます。
コンポーネントはその実行時に必ず使用する出力コネクタセットのデフォルトコネクタにストリームをセットしなければなりません。
それぞれの出力コネクタにはストリームファクトリを持ちます。
ストリームファクトリはデザイナー上で定義されたストリームプロパティとフィールド定義を保持し、ストリームを生成するためのFactoryクラスとなります。
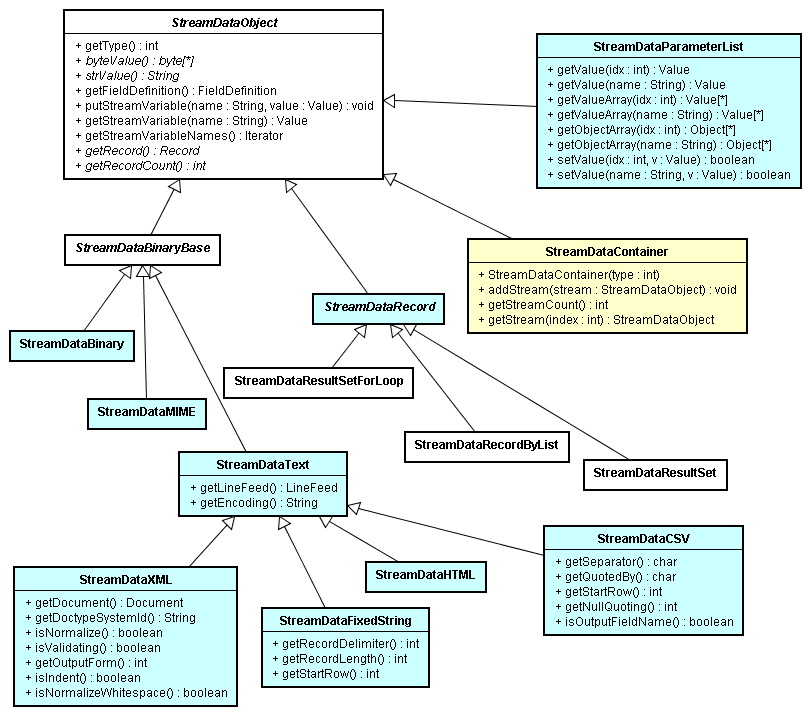
ここまでに説明された概念をクラス図で示します。
Component クラスはフローサービス内で実行されるすべてのコンポーネントの抽象基底クラスです。
Componentではいくつかのabstractメソッドと何もしない空メソッドが定義されています。
入出力コネクタがひとつだけのシンプルなコンポーネントを作成する場合は、Componentを1段階凡化したSimpleComponent クラスを
継承して作成することでさらに簡単にコンポーネントを作成することができます。
/**
* コンポーネントの実行コードを記述します
*/
public abstract boolean execute(ExecuteContext context) throws FlowException;
コンポーネント開発者にとって最も重要な意味を持つメソッドはexecuteメソッドです。
実際の所ループを処理しない単純なコンポーネントを作成する場合は実装するメソッドはほとんどこのメソッドのみとなります。
ファイルを取得する
ファイルをコピーする
RDBにデータを書き込む
WebServiceを実行する
Excelファイルを作成する
ほんの数行のコードで実現可能な処理から、一般のSIerには馴染みの無いような複雑な処理まで、Javaで可能なことであればどんな処理であっても
コンポーネント化することができます。
executeメソッドの返り値はそのコンポーネントがループの起点となるかどうかを示すbooleanです。RecordGetコンポーネント では指定の行数を読み込んだあとに
データがまだ残っている場合は残りのデータをループで処理するのでfalseを返します。
/** ループ処理の実行コードを記述します */
public int executeLoop(ExecuteContext context) throws FlowException {
return LOOP_END;
}
ループの起点となるコンポーネントで実際にループ時の処理を記述するメソッドがexecuteLoopメソッドです。
上記はComponentクラスで実装されているexecuteLoopメソッドのデフォルトの実装です。
ループの起点となるコンポーネントではこのメソッドをオーバーライドしてループ時の処理を記述します。
LOOP_END Loop処理を実行し、Loopは終了した
LOOP_CONTINUE Loop処理を実行し、Loopは継続する
LOOP_NOTHING Loop処理は実行されなかった
メソッドの実行によりループで処理すべき内容がすべて完了した場合にはLOOP_ENDを返し、
さらにループによってこのコンポーネントに戻ってきて欲しい(=まだ処理すべきデータがある)場合には
LOOP_CONTINUEを返します。
注意が必要なのはexecuteLoopメソッドはコンポーネントがループの起点となっている場合に処理を行うメソッドであり、
ループの中でコンポーネントが実行される場合に呼び出されるメソッドはexecuteメソッドであるという点です。
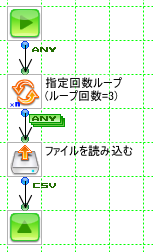
左記のフローでは回数を指定してループするコンポーネント(LoopStartコンポーネント )で3回のループを行っています。
LoopStartコンポーネントの前にさらに別のLoopStartコンポーネントを置く(つまりループをネストさせる)こともできますが、
その場合コンポーネント自身がループの起点となっている場合以外に実行されるメソッドはexecuteメソッドです。
コンポーネントのインスタンスはリクエストを受けてフローが初期化されたタイミングで生成されます。
これがコンポーネント開発者にとってどういう意味を持つかと言うと、コンポーネントの状態をメンバー変数に保存しておいても構わないと言うことです。
例えばLoopStartコンポーネント はexecuteメソッド内でプロパティ値から取得したループ回数をメンバー変数に設定し、
executeLoopメソッドでそれをデクリメントしています。
それ以外にもComponentクラスにはフローの実行の過程でコールバックされるメソッドがいくつかあります。
/** 初期化処理を記述します */
public void init(ExecuteContext context) throws FlowException {
}
initメソッドはコンポーネントで初期化処理を行いたい場合に実装します。
initメソッドではexecuteやexecuteLoopメソッドで繰り返し使用するオブジェクトをメンバー変数に設定しても構いません。RDBGetコンポーネント ではDB接続に使用するコネクションをinitメソッド内で取得します。
/** 終了処理を記述します */
public void term(ExecuteContext context) {
}
termメソッドはコンポーネントで終末処理を行いたい場合に実装します。
initメソッドが実行が完了しなかった場合(FlowExceptionをthrowした場合)はtermメソッドやendFlowメソッドは実行されないことに注意してください。
またNextフローがある場合はtermメソッドはNextフローの実行よりも前に実行されます。(Nextフローはフローの終了時に続けて次のフローを実行する機能なので、
それが実行される時には先に実行したフローは完全に終了しています。)Releasable インターフェースを使用してください。
/** 個別のフロー実行終了時の処理を記述します */
public void endFlow(ExecuteContext context) {
}
endFlowメソッドはコンポーネントでフロー終了時の処理を行いたい場合に実装します。
endFlowメソッドは各フローの終了時に毎回実行される
endFlowメソッドはサブフロー内のコンポーネントは対象としない
フローがトランザクション化されている場合はendFlowメソッドはTransactionManagerのcommitまたはrollback後に実行されます。
/**
* コンポーネントのキャンセル処理を記述します。
* キャンセル処理が正しく行えた場合はtrueを返します。
* (デフォルトの実装では常にfalseを返します。)
*/
public boolean cancel() {
return false;
}
cancelメソッドではコンポーネントの強制終了処理を実装します。
強制終了は原則的に一つのコンポーネントの実行が終わり次のコンポーネントの実行に遷移するタイミングで実行されます。
つまりcancelメソッドではそのコンポーネントのexecute(またはexecuteLoop)の処理を中断しそこから抜けるような処理を記述します。
強制終了時のキャンセル実装の詳細については後述のキャンセル処理の実装 の章を参照してください。
各メソッドがどういうタイミングで実行されるかはそのメソッド内でログを出してみると良くわかります。
MethodLogコンポーネントのソース
MethodLogコンポーネントの定義ファイル
ExecuteContext はフローの実行コンテキストを表すクラスです。
このクラスを用いることで
ログ出力
変数の取得
共有オブジェクトの引き回し
プロジェクトオーナーの取得
実行ユーザーの取得
セッションの取得
コネクションの取得
トランザクションの追加
を行うことができます。
本製品ではログ出力のライブラリとしてApache Jakarta Projectの Log4Jを使用しています。
ExecuteContextには以下のログ出力用のメソッドがあり、それぞれのメソッドに文字列を渡した場合のログの出力形式(Log4Jのパターン"%m"に対応)は以下のようになります。
メソッド 出力形式
debug メッセージコード : [リクエストID ] デバッグ(コンポーネント名 ) :メッセージ
debugInfo メッセージコード : [リクエストID ] デバッグ情報(コンポーネント名 ) :メッセージ
info メッセージコード : [リクエストID ] 情報(コンポーネント名 ) :メッセージ
warn メッセージコード : [リクエストID ] 警告(コンポーネント名 ) :メッセージ
error メッセージコード : [リクエストID ] エラー(コンポーネント名 ) :メッセージ
fatal メッセージコード : [リクエストID ] 致命的エラー(コンポーネント名 ) :メッセージ
debugInfo以外の各メソッドはLog4Jのlevelに対応しています。
フローの実行ログのカテゴリは
asteria.flow.プロジェクトオーナー名 .プロジェクト名 .フロー名
というカテゴリになります。(プロジェクトオーナー名はドメインを含むフルネームで、ドメインは「.」で区切られます。)
各種変数は以下のメソッドで取得することができます。
注意
Value クラスには値の設定メソッドがありますが、コンポーネントの中でフロー変数などに直接値を設定してはいけません。
関連する複数のコンポーネントをひとつのフローの中で使用する場合、それらのコンポーネントで同じオブジェクトを共有したい場合があります。IndependentMapの使用 の章を参照してください。
それぞれ getProjectOwnerメソッドとgetUserメソッドで取得することができます。
セッション(FlowSession )はgetSessionメソッドで取得することができます。
またセッションは内部にMapを保持しておりこのMapにはSDKユーザーが独自に値を設定することが可能です。(get/put/removeメソッド)
設定したオブジェクトがセッション終了時やタイムアウト時にファイナライズ処理を必要とする場合はSessionListener を追加してください。
getConnectionメソッドによってコネクションを取得することができます。
コネクション種別(String)とコネクション名(String)を引数とするメソッド
コネクションプロパティ(ConnectionProperty)を引数とするメソッド
の二つがあります。(実際には種別と名前を指定するメソッドは内部的にConnectionPropertyを生成して後のメソッドを実行しています。)
指定したコネクションが存在しない場合はExceptionとなります。
取得するコネクションが既にフロー内で使用されている場合は、これらのメソッドで取得できるコネクションのインスタンスは先に使用されたコネクションと同じになります。RDBConnection を取得しようとした場合に、それ以前にRDBGet/RDBPutなどのコンポーネント
が「TEST1」というコネクションを使用していた場合は取得されるコネクションは先に使用されたものと同じインスタンスになります。
コネクションの使用方法の詳細についてはコネクションの使用 の章を参照してください。
コンポーネントがトランザクションをサポートする場合はexecuteまたはexecuteLoopメソッド内で
Transactionインターフェース(またはそれを拡張したExtendedTransactinインターフェース)を実装したクラスを作成して、ExecuteContext#addTransactionメソッドに渡します。
トランザクションの使用方法の詳細についてはトランザクション の章を参照してください。
コンポーネント開発のとっかかりとして、まずは何も処理を行わず入力ストリームをそのまま出力するだけのコンポーネントのソースを以下に示します。
import com.infoteria.asteria.flowengine2.execute.ExecuteContext;
import com.infoteria.asteria.flowengine2.flow.InputConnector;
import com.infoteria.asteria.flowlibrary2.FlowException;
import com.infoteria.asteria.flowlibrary2.component.SimpleComponent;
import com.infoteria.asteria.flowlibrary2.stream.StreamType;
public class DoNothingComponent extends SimpleComponent {
public static final String COMPONENT_NAME = "DoNothing";
public String getComponentName() { return COMPONENT_NAME;} //1
public DoNothingComponent() { //2
getInputConnector().setAcceptLinkCount(1); //3
//getInputConnector().setAcceptContainer(true); //4
//getInputConnector().setExpandContainer(false); //5
getInputConnector().setAcceptType(StreamType.ALL); //6
getOutputConnector().setAcceptType(StreamType.ALL); //7
}
public boolean execute(ExecuteContext context) throws FlowException {//8
passStream(); //9
return true; //10
}
}
数字のコメントがついている個所ではそれぞれ以下のことを行っています。
コンポーネント名を返すメソッド
ここで定義したコンポーネント名と定義ファイルのComponent/@name属性の設定値は同じにしなければなりません。
コンポーネントには引数なしのコンストラクタが必要です。
入力コネクタが受け入れることのできるストリームの最大値を設定しています。
getInputConnector().setAcceptLinkCount(InputConnector.LINK_UNBOUNDED);
のように InputConnector#LINK_UNBOUNDEDというシンボルを使用して値を設定します。
コネクタがストリームコンテナを受け入れるかどうかを設定しています。(ストリームコンテナについては後述します。)
コネクタがストリームコンテナを受け入れた時にそれを展開するかどうかを設定しています。
入力コネクタが受け入れ可能なストリームフォーマットを指定しています。StreamType クラスで宣言されているシンボルを使用します。
getInputConnector().setAcceptType(StreamType.TEXT|StreamType.HTML);
のように設定します。
出力コネクタが受け入れ可能なストリームフォーマットを指定しています。
3〜7の入出力コネクタの設定はコンポーネント作成の際には必ず設定する必要のある項目です。
executeメソッド
passStreamメソッドを使用すると入力ストリームがそのまま出力ストリームとしてセットされます。
StreamDataObject os = ...;//出力ストリームを作成する。(後述)
setOutputStream(os);
のように作成したストリームをSimpleComponent#setOutputStreamメソッドで設定します。
このコンポーネントはループの起点とならないので常にtrueを返しています。
このコンポーネントのソースコードと定義ファイルはsampleフォルダにもあります。
DoNothingコンポーネントのソース
DoNothingコンポーネントの定義ファイル
このコンポーネントは何もしないのでコンパイルして動かしてみても何も起きません。
コンポーネント開発の上でもうひとつ重要な要素としてプロパティがあります。
逆から言えばコンポーネント開発者は自作コンポーネントの機能のうちフロー開発者に値を設定させたいものをプロパティにします。
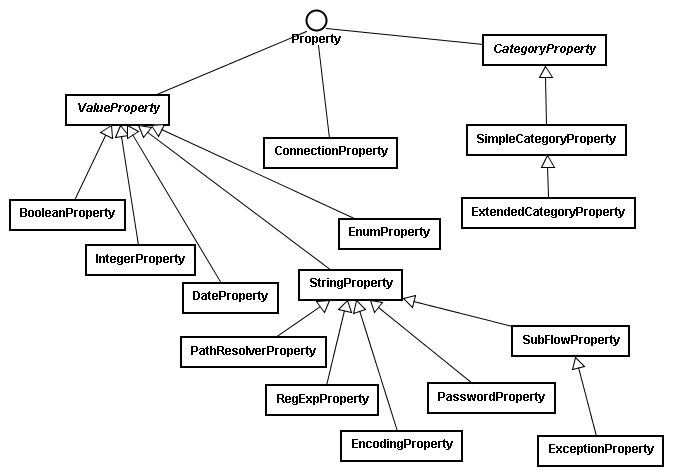
サーバー側に標準で組み込まれているプロパティクラスの一部のクラス図を以下に示します。
実装的にはプロパティとはProperty インターフェースを実装したクラスのことです。
図ではPropertyインターフェースの直接の実装クラスとして、ValueProperty、CategoryProperty、ConnectionPropertyの3つがありますが、以下にそれぞれの概要を説明します。
ValueProperty はインスペクタ上でプロパティ名と値が1対1で対応するプロパティの抽象基底クラスです。
設定値のデータ型により、StringProperty 、IntegerProperty などの具象クラスがあります。
StringPropertyからさらに派生したプロパティは、なんらかの付加機能があるプロパティです。RegExpProperty にはプロパティ値として正規表現が設定されるのでそれに文字列がマッチするかどうかを判断するmatchメソッドが加えられています。PathResolverProperty にはプロパティ値としてファイルパスが設定されるので、それが相対パスであろうと絶対パスであろうと適切に対応するFileオブジェクトを取得する
getFileメソッドがあります。
CategoryProperty はインスペクタ上でタブページとして表示されるプロパティに対応します。
列項目として名前、データ型、デフォルト値の3つを持つものがSimpleCategoryProperty で、
それ以上の項目が必要な場合はExtendedCategoryProperty を使用します。
ConnectionProperty はFSMCやデザイナーで定義した各種コネクションを使用するためのプロパティです。コネクションの使用 の章を参照してください。
プロパティを定義するにはコンポーネントのコンストラクタ内で作成したPropertyをregistPropertyメソッドで登録します。
import com.infoteria.asteria.flowengine2.execute.ExecuteContext;
import com.infoteria.asteria.flowengine2.flow.InputConnector;
import com.infoteria.asteria.flowlibrary2.FlowException;
import com.infoteria.asteria.flowlibrary2.component.SimpleComponent;
import com.infoteria.asteria.flowlibrary2.stream.StreamType;
import com.infoteria.asteria.flowlibrary2.property.*;
import com.infoteria.asteria.connection.RDBConnection;
import com.infoteria.asteria.connection.RDBConnectionEntry;
import java.util.Iterator;
import java.sql.Connection;
import java.sql.SQLException;
/**
* Propertyのテストコンポーネント
*/
public class PropertyTestComponent extends SimpleComponent {
public static final String COMPONENT_NAME = "PropertyTest";
public String getComponentName() { return COMPONENT_NAME;}
private IntegerProperty propA = new IntegerProperty("A", true, true);
private IntegerProperty propB = new IntegerProperty("B", true, true);
private IntegerProperty propC = new IntegerProperty("C", false, true);
private SimpleCategoryProperty propCategory = new SimpleCategoryProperty("MyCategory");
private StringProperty propLogMethod = new StringProperty("LogMethod", true, false);
private ConnectionProperty propConnection = new ConnectionProperty(RDBConnectionEntry.TYPE, "Connection", false);
private StringProperty propDriver = new StringProperty("DriverName", false, true);
public PropertyTestComponent() {
getInputConnector().setAcceptLinkCount(1);
//getInputConnector().setAcceptContainer(true);
//getInputConnector().setExpandContainer(false);
getInputConnector().setAcceptType(StreamType.ALL);
getOutputConnector().setAcceptType(StreamType.ALL);
//プロパティの登録
registProperty(propA);
registProperty(propB);
registProperty(propC);
registProperty(propCategory);
registProperty(propLogMethod);
registProperty(propConnection);
registProperty(propDriver);
}
public boolean execute(ExecuteContext context) throws FlowException {
//プロパティ「A」と「B」に値を設定してその和をプロパティ「C」に設定する。
int a = propA.intValue();
int b = propB.intValue();
propC.setValue(a + b);
//プロパティ「MyCategory」に設定したNameと値をプロパティ「LogMethod」で指定されたメソッドでログに出力する。
Iterator it = propCategory.keySet().iterator();
while (it.hasNext()) {
String name = (String)it.next();
String msg = name + " = " + propCategory.getValue(name);
outputLog(context, msg);
}
//プロパティ「Connection」に設定されたRDBConnectionのドライバー情報をプロパティ「DriverName」に設定する。
if ( !propConnection.isNull()) {
RDBConnection rcon = (RDBConnection)context.getConnection(propConnection);
Connection con = rcon.getConnection();//ここで取得したjava.sql.Connectionは自由に使用することが出来る。
try {
propDriver.setValue(con.getMetaData().getDriverName());
} catch (SQLException e) {
//例外が発生した場合はそのメッセージをプロパティに設定する
propDriver.setValue(e.toString());
}
}
passStream();
return true;
}
private void outputLog(ExecuteContext context, String msg) {
String method = propLogMethod.strValue();
if (method.equals("fatal"))
context.fatal(msg);
else if (method.equals("error"))
context.error(msg);
else if (method.equals("warn"))
context.warn(msg);
else if (method.equals("info"))
context.info(msg);
else if (method.equals("debugInfo"))
context.debugInfo(msg);
else if (method.equals("debug"))
context.debug(msg);
}
}
executeメソッド内で行っている処理の内容には特に意味はありません。
プロパティの登録
プロパティ値の取得
プロパティ値の設定
次にこのコンポーネントの定義ファイルを示します。
<?xml version="1.0" encoding="utf-8"?>
<ComponentDefine version="4.0" xmlns="http://www.infoteria.com/asteria/flowengine/definition">
<xsc lang="en">
<Component category="Sample" icon="" name="PropertyTest" toolTip="PropertyTest">
<Class>PropertyTestComponent</Class>
<Property name="Exception" mapping="false" toolTip="" type="exception"/>
<Property name="A" required="true" toolTip="A" type="int">0</Property>
<Property name="B" required="true" toolTip="B" type="int">0</Property>
<Property name="C" readonly="true" mapping="input" toolTip="A+B" type="int">0</Property>
<Property name="LogMethod" choiceItem="fatal
error
warn
info
debugInfo
debug" mapping="false" required="true" toolTip="Log method" type="choice">info</Property>
<Property name="Connection" connection="RDBConnection" mapping="false" toolTip="RDBConnection" type="connection"/>
<Property name="DriverName" readonly="true" mapping="input" toolTip="DriverName" type="string"/>
<Category key="Name" name="MyCategory">
<Property name="Name" toolTip="Name" type="string"/>
<Property name="Default" toolTip="Default value" type="string"/>
</Category>
<Input accept="ALL"/>
<Output streamPassThrough="true"/>
</Component>
</xsc>
<xsc lang="ja">
<Component category="Sample" icon="" name="PropertyTest" toolTip="プロパティテスト">
<Class>PropertyTestComponent</Class>
<Property name="Exception" displayName="汎用" mapping="false" toolTip="" type="exception"/>
<Property name="A" displayName="値A" required="true" toolTip="A" type="int">0</Property>
<Property name="B" displayName="値B" required="true" toolTip="B" type="int">0</Property>
<Property name="C" displayName="値C" readonly="true" mapping="input" toolTip="A+B" type="int">0</Property>
<Property name="LogMethod" displayName="ログメソッド" choiceItem="fatal
error
warn
info
debugInfo
debug" mapping="false" required="true" toolTip="Log method" type="choice">info</Property>
<Property name="Connection" displayName="コネクション名" connection="RDBConnection" mapping="false" toolTip="RDBConnection" type="connection"/>
<Property name="DriverName" displayName="ドライバー名" readonly="true" mapping="input" toolTip="DriverName" type="string"/>
<Category key="Name" name="MyCategory" displayName="カテゴリー" >
<Property name="Name" displayName="名前" toolTip="Name" type="string"/>
<Property name="Default" displayName="値" toolTip="Default value" type="string"/>
</Category>
<Input accept="ALL"/>
<Output streamPassThrough="true"/>
</Component>
</xsc>
</ComponentDefine>
定義の詳細については定義ファイルリファレンス を参照してください。
英語版と日本語版
ソースコードでのプロパティ登録との対応
デザイナーの振る舞いを決定する属性の定義
入力ストリームをそのまま出力する定義
ここではでてきませんが、SimplePropertyControllerというデザイナーのプラグインを使うことでプロパティの表示/非表示をコントロールすることも可能です。HTTPGetコンポーネント では「コネクションを使用」というプロパティ値によってURLを指定するために使用する(=デザイナーで表示される)プロパティが異なります。
整合性をとりながらフロー開発者が少しでもコンポーネントを使いやすくなるようにプロパティを設計してください。
ストリームとはフローを流れていくデータのことです。
種別 クラス 説明
Binary StreamDataBinary バイナリーデータ
Text StreamDataText テキストデータ
HTML StreamDataHTML HTMLデータ
MIME StreamDataMIME MIMEデータ
Record StreamDataRecord 行と列を持つレコード形式データ
CSV StreamDataCSV CSVデータ。行と列を持つレコード形式データでもある
FixedLength StreamDataFixedString 固定長データ。行と列を持つレコード形式データでもある
ParameterList StreamDataParameterList 主にHTMLのフォームやSOAPのパラメーターを扱うためのデータ
XML StreamDataXML XMLデータ。DOMで扱うことができ、また繰り返し構造をレコード形式で扱うこともできる
また、これらのストリームをまとめて扱うための枠組みとしてコンテナ(StreamDataContainer)があります。
ストリームを扱うコンポーネントを作成する場合、次のことを決める必要があります。
入力ストリームとして何を受け入れることができるのか?
複数の入力ストリームを受け入れるようにするか?
出力ストリームとして何を出力するのか?
コンテナを扱うことができるのか?
多くの場合、コンポーネントで扱うストリームはひとつだけであり複数の入力ストリーム(あるいはコンテナ)を検討しなければならないケースはあまりありません。XSLTコンポーネント は入力としてひとつのXMLストリームを受け入れ、それを変換して出力ストリームを作成します。)メールコンポーネント の添付ファイルのように複数ストリーム、あるいはコンテナでなければ素直に実装できない処理もなかには存在します。
ストリーム関連のクラスのクラス図を以下に示します。
ストリームの操作で使用するほとんどのメソッドは基底クラスであるStreamDataObjectで定義されています。
これ以外にStreamDataXMLにはDOMのDocumentを取得するためのgetDocumentメソッドがあり、
StreamDataParameterListにはパラメーター値を設定/取得するためのメソッドがあります。
StreamDataRecordにはさらにサブクラスとしてデータをListで扱うためのクラスとJDBCのResultSetをラップしたクラスがありますが、
通常コンポーネント開発者がこれらのクラスを意識することはありません。
入力ストリームはInputConnector から取得します。StreamDataObject を取得し、
複数ストリームの受け入れが可能なコンポーネントではInputConnector#getStreamArrayメソッドで、StreamDataObject の配列を取得します。
コンテナを扱うコンポーネントの場合はInputConnector#setExpandContainerを設定しておくことで、コンテナをgetStreamArrayメソッドでばらして取得することもできます。
例えばメールコンポーネント はサブコネクタで複数ストリームもコンテナも扱うことのできるコンポーネントですが、どちらの場合もそれらをすべて添付ファイルとするので、
最初にExpandContainerを設定しておけばコンポーネント内部の処理ではコンテナを意識する必要はなくなります。
StreamDataObjectにはbyteValue, strValue, getRecordという3つのメソッドがあり、それぞれストリームのバイナリ値、文字列値、レコードを取得することが出来ます。
これ以外にStreamDataXMLにはDOMのDocumentを取得するためのgetDocumentメソッドがあり、
StreamDataParameterListにはパラメーター値を設定/取得するためのメソッドがあります。
コンポーネントはこれらのメソッドを使用して入力ストリームのデータにアクセスしながら処理を行います。
種別 メソッド 取得されるオブジェクト
すべて byteValue byte[]
strValue java.lang.String
getRecord com.infoteria.asteria.flowlibrary2.stream.Record
XML getDocument org.w3c.dom.Document
ParemterList getValue Value
getValueArray Value[]
getObjectArray Object[]
StreamDataParameterListのgetValueArray, getObjectArrayメソッドはフィールドが配列の場合に使用するメソッドです。
それぞれのストリームで、byteValue、strValue、getRecordメソッドが返す内容は以下のようになります。
種別 byteValue strValue getRecord
Binary バイナリーデータそのもの バイナリーデータの16進ダンプ 「Object」というフィールド名でBinary型の1行1列のレコード
Text テキストデータをエンコーディングでバイト列化したもの テキストデータそのもの 「Object」というフィールド名でString型の1行1列のレコード
HTML HTMLデータをエンコーディングでバイト列化したもの HTMLデータそのもの 「Object」というフィールド名でString型の1行1列のレコード
MIME MIMEデータのバイト列 MIMEデータをヘッダのcharsetで文字列化したもの 「Object」というフィールド名でBinary型の1行1列のレコード
Record RecordのXML表現 RecordのXML表現 フィールド定義に沿ったレコード
CSV CSVデータをエンコーディングでバイト列化したもの CSVデータそのもの フィールド定義に沿ったレコード
FixedLength 固定長データそのもの 固定長データをエンコーディングで文字列化したもの フィールド定義に沿ったレコード
ParameterList ParameterListのXML表現 ParameterListのXML表現 フィールド定義に沿い、配列フィールドの長さだけ行を持つレコード
XML XMLそのもの XMLそのもの フィールド定義に沿ってXMLの繰り返しをレコード化したもの
コンテナ コンテナ内の各ストリームのbyteValueを連結したもの コンテナ内の各ストリームのstrValueを連結したもの コンテナ内の各ストリームのレコードすべて
グレイになっているメソッドは通常は使用しないメソッドです。
また、コンテナではgetRecordメソッドは各ストリームのレコードに透過的にアクセスできます。
getRecordメソッドを使用してコンテナを意識することなく扱う
コンテナをばらしてそれぞれを個別のストリームとして扱う
のいずれかなのでほとんど使用されることはありません。
入力ストリームを扱う際の注意
これらのメソッドで取得されるバイト列やRecord、StreamDataXMLのDocumentなどに対して直接変更を加えてはいけません。
ストリームのRecord インターフェースはStreamDataObject#getRecordメソッドにより取得されます。
ここで取得されたRecordにどのようなフィールドがあるかという情報を保持しているのはFieldDefinitionというクラスであり、
それはStreamDataObject#getFieldDefinitionというメソッドで取得できます。
Recordインターフェースはストリーム内の各レコードのイテレータになっていて、getRecordメソッドで取得された時点でそのポインタは先頭レコードを指しています。
StreamDataObject is;
Record record = is.getRecord();
while (record != null) {
Value v1 = record.getValue("Field1");
Value v2 = record.getValue("Field2");
//ここで何かv1, v2を用いた処理を行う
record = record.nextRecord();
}
Recordインターフェースにはnext以外にもabsoluteなどレコード番号を指定して各レコードにアクセスするメソッドもありますが、これらのメソッドはストリームの
種類によってはパフォーマンスが悪いことがあるので、可能な限りnextを使用してレコードを先頭からなめるようなアクセス方法で使用してください。
Record#getValueの注意
ストリームの種類によってはgetValueメソッドの返すValueオブジェクトのインスタンスがRecordをイテレートしても同じインスタンスを返すものがあります。
StreamDataObject is;
Record record = is.getRecord();
Value preValue = null;
while (record != null) {
Value v1 = record.getValue("Field1");
Value v2 = record.getValue("Field2");
if (preValue != null && preValue.equals(v1)) {
//Field1の値が直前のレコードと同じだった場合に何かする
}
preValue = v1;
record = record.nextRecord();
}
この場合ストリームの種類によってはpreValueとv1が同じインスタンスになるので意図したとおりには動作しません。
StreamDataObject is;
Record record = is.getRecord();
String preValue = null;
while (record != null) {
Value v1 = record.getValue("Field1");
Value v2 = record.getValue("Field2");
if (preValue != null && preValue.equals(v1.strValue())) {
//Field1の値が直前のレコードと同じだった場合に何かする
}
preValue = v1.strValue();//Value#strValue()はnullを返すことはありません。
record = record.nextRecord();
}
入力ストリームがコンテナ(StreamDataContainer )だった場合にそれがどのように扱われるかはInputConnector#setAcceptContainerとInputConnector#setExpandContainerの設定値によって決まります。
true false
AcceptContainer コンテナを受け入れる 入力ストリームにコンテナがあった場合は
ExpandContainer InputConnector#getInputStreamArrayを使用した時に コンテナはコンテナのまま取得される
コンポーネントがコンテナをどのように扱うかはそのコンポーネントの設計によりますが、可能な限り受け入れるようにしておいた方がフロー開発者の利便性はあがります。
入力ストリームを使用しない場合はコンテナを受け入れるFileGetコンポーネント のように入力ストリームを全く使用しないコンポーネントや、Logコンポーネント のように入力ストリームをそのまま出力するだけのコンポーネントでは
コンテナを意識する必要はまったくないのでコンテナを受け入れ可能として問題ありません。
入力ストリームをRecordとして処理する場合はコンテナを受け入れるRecordFilterコンポーネント のように入力ストリームに対してRecordインターフェースでアクセスするコンポーネントはコンテナを受け入れます。
複数ストリームを受け入れる場合はコンテナを展開するメールコンポーネント の添付ファイルやZipコンポーネント のような複数のストリームを並列に扱うコンポーネントの場合は、
コンテナを展開して扱うようにした方がFileGetコンポーネント のようなコンテナを出力するコンポーネントとの相性が良くなります。
特定のストリームのみを扱う場合はコンテナを受け入れないXSLTコンポーネント などのようにXMLストリームのみを扱うコンポーネントの場合はコンテナを受け入れないこととした方がすっきりします。
ストリーム自身の属性はデザイナー上ではストリームプロパティとして定義されます。
デザイナーで設定されたストリームプロパティを保持しているのはStreamFactoryというクラスです。
ストリームを作成する場合はこのStreamFactoryのcreateメソッドにストリーム内容のデータを渡します。
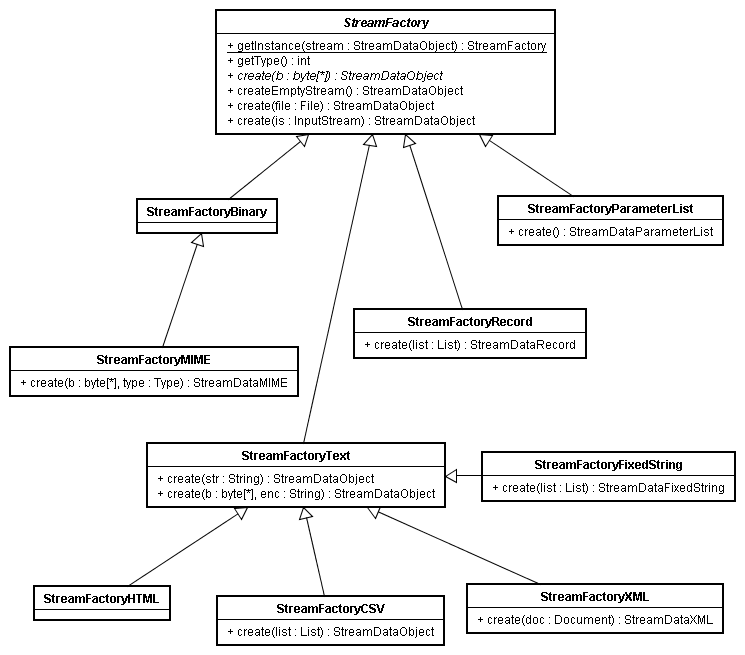
StreamFactoryのクラス図を以下に示します。
基底クラスであるStreamFactoryではbyte[]を引数とするcreateメソッドがあります。
以下にそれぞれのストリームを作成する場合にどのようなデータを引数として渡せば良いかを説明します。
StreamDataBinary はbyte[]を引数として作成します。
StreamDataText は通常はStringを引数として作成します。
StreamDataHTML の作成方法はStreamDataTextとすべて同じです。
StreamDataTextとStreamDataHTMLの違いは、MIMEに変換した場合(ブラウザから実行するフローで結果ストリームとして返された場合)に
Content-Typeが「text/plain」となるか「text/html」となるかだけです。
StreamDataMIME の作成ではbyte[]とMIMEType(StreamDataMIME.Type)を引数として指定します。
実際にはエンドユーザーのレベルではMIMETypeについてほとんど気にする必要がありません。
StreamDataCSV の作成方法にはStreamDataTextと同じ作成方法の他に、java.util.Listを引数とするメソッドがあります。
このメソッドを使用する場合、Listの内容はフィールド定義で定義されたフィールド数と同じ要素数を持つString[]のリストとなっていなければなりません。
(Listの各アイテムが1行分のレコードデータとなります。)
Stringやbyte[]を引数とする場合はその内容はストリームプロパティで指定された区切り文字で区切られたCSVデータでなければなりませんが、
囲み文字については指定されている場合でも各フィールドが必ずしもその囲み文字で括られている必要はありません。
StreamDataFixedString の作成方法にはbyte[]、String、Listをそれぞれ引数とする3つがあります。
StreamDataXML の作成方法にはbyte[]、String、org.w3c.dom.Documentをそれぞれ引数とする3つがあります。
Documentを引数としてStreamDataXMLを作成する場合、そのDocumentはNamespace awareなDocumentでなければなりません。
※ DOMUtilはJAXPをラップしたDOMを扱うためのユーティリティクラスです。内部的にはXercesを使用しています。
StreamDataRecord を作成する場合は通常はListを引数とするメソッドを使用します。
byte[]を引数とするメソッドを使用するメソッドにStreamDataRecord#byteValueの出力内容を渡せば、その内容と同じRecordストリームが作成されますが、
Recordストリームのバイナリ値は主としてデバッグ用途のためだけに用意されているものなので、基本的にはこのメソッドを使用してはいけません。
StreamDataParameterList を作成する場合は引数無しのcreateメソッドを使用します。
byte[]を引数とするメソッドを使用するべきではないのはStreamDataRecordの場合と同じです。
出力ストリームとしてコンテナを出力する場合はStreamDataContainer を作成して、そこにストリームを追加していきます。
出力ストリームとしてコンテナを使用することがあるのはほとんどの場合、外部ストレージからデータを取得するコンポーネントです。
FileGetコンポーネント
FTPGetコンポーネント
POP3コンポーネント
IMAPコンポーネント
UNZIPコンポーネント
これらのコンポーネントでは取得対象のデータをコンテナ化して、出力するかループでひとつずつ出力するかを選択できるようになっています。
ストリーム変数とはストリームがそのデータ内容とは別に持つ属性情報です。
コンポーネント内でストリーム変数を取得/設定するには、StreamDataObject#getStreamVariable/putStreamVariableメソッドを使用します。
コンポーネントが出力ストリームに対して値を設定する。
外部ストレージからデータを取得するコンポーネントの多くはそのデータ自身に関する情報をストリーム変数に設定します。
あるいはPOP3コンポーネントのようにフロー開発者が自分の取得したいメールヘッダーをCategoryPropertyとして設定することによりそれがストリーム変数となるものもあります。
これらの値を出力専用のコンポーネントプロパティではなく、ストリーム変数として設定することには次のようなメリットがあります。
ストリーム単位で値を設定できる
入力をそのまま出力するコンポーネントをまたいでマッパーで使用できる
FileGetコンポーネントのように固定の変数名でストリーム変数を設定する場合は定義ファイルのOutput要素以下に付加する変数の定義を追加します。
<Output accept="Binary;Text;HTML;CSV;FixedLength;XML;MIME" default="XML">
<Variables>
<Field name="FilePath" type="String"/>
<Field name="FileDate" type="DateTime"/>
<Field name="FileSize" type="Integer"/>
</Variables>
</Output>
POP3コンポーネントのようにCategoryPropertyをそのままストリーム変数とする場合はCategory要素に「streamVariables="true"」という属性を追加します。
<Category displayName="メールヘッダー" key="Name" mapping="input" name="MailHeaders" streamVariables="true" >
<Property choiceItem="Message-Id
Reply-To
In-Reply-To
Content-Type
Date
References
X-Mailer"
displayName="ヘッダー名" name="Name" toolTip="header name" type="editableChoice"/>
</Category>
定義の詳細は定義ファイルリファレンス を参照してください。
コンポーネントが入力ストリームに対して固定の変数名で値があることを期待して、それがある場合はその値を使用する。
複数のストリームを扱うコンポーネントには処理に使用する値をストリーム変数から取得するものがあります。メールコンポーネント は添付ファイルのファイル名をFilePathというストリーム変数から取得します。
添付ファイルは複数ある場合があるので、そのファイル名をコンポーネントプロパティとして設計した場合、2つ目以降のストリームにファイル名をつけることができません。
先にも述べたとおり、定義ファイルでOutput要素にstreamPassThrough属性を定義した場合、入力ストリームをそのまま出力すると言う定義となります。
この場合、そのコンポーネント(正確には出力コネクタ)では直前に接続したコンポーネントのストリーム定義が参照されるようになります。
通常このような定義を行った場合はコンポーネント側でも入力ストリームをそのまま出力するように作成しますが必ずそうしなければならないという事ではありません。RecordFilterコンポーネント は定義ファイル上ではstreamPassThroughとなっていますが、ソースコード上では入力ストリームをフィルタリングして
新しいストリームを作成して出力しています。
このようなコンポーネントを作成する場合は、StreamFactory#getInstanceメソッドにより入力ストリームのストリーム定義をコピーしたStreamFactoryを取得して使用します。
InputStream is = getInputConnector().getStream();
StreamFactory factory = StreamFactory.getInstance(is);//入力ストリームと同じ定義のStreamFactoryを生成
...
コンポーネントによってはフロー開発者にフィールド定義を行わせる必要がなく、常に固定のフィールド定義となっていれば良いものがあります。FileListコンポーネント ではファイルの各種属性情報を列として持つRecordストリームに定義が固定されています。
このようなコンポーネントを作成する場合は、定義ファイルにフィールド定義を追加した上でreadonlyとします。
<Output accept="Record">
<FieldDef readonly="true" >
<Field name="FileName" type="String"/>
<Field name="FilePath" type="String"/>
<Field name="FileDate" type="DateTime"/>
<Field name="FileSize" type="Integer"/>
<Field name="FileType" type="String"/>
</FieldDef>
</Output>
上記定義で「readonly="true"」を外した場合は初期状態で指定のフィールド定義が設定されますが編集は可能となります。
ここまで説明してきたとおりフローサービスのコンポーネントデザインではストリーム定義は出力ストリームに対して行うこととなっています。
しかしコンポーネントによっては出力ストリームではなく、入力ストリームを規定したいものがあります。RDBPutコンポーネント で、このコンポーネントではRDBのテーブルから更新する列を選択して、
それを入力ストリームのフィールド定義とします。
<Input accept="Record" defineStream="true" >
<FieldDef readonly="true"/>
</Input>
</Output streamPassThrough="true"/>
RDBPutコンポーネントではフィールド定義は専用のテーブル選択ダイアログを使用して行うので、FieldDefがreadonlyとなっていますが
Input要素以下の定義方法はOutput要素の場合と同じです。
このように入力ストリームを定義する、とした場合その定義はデザイナーによって直前にリンクされたコンポーネントの出力ストリーム定義にコピーされます。
これがどういうことかというと、コンポーネントのソースコード側には「入力ストリームを定義する」という概念は存在しないと言うことです。
ループとはコンポーネントを実行し、後続のフローを実行した後に再びそのコンポーネントに戻ってきて以降の処理を繰り返すことです。executeメソッドとexecuteLoopメソッド の章でも述べたとおり、ループをサポートするコンポーネントではexecuteメソッドだけではなく、
executeLoopメソッドも併せて実装します。
またコンパイラにそのコンポーネントがループする可能性があることを通知するためにloopPossibilityメソッドもオーバーライドします。
ループの例として最も単純なものは標準で提供されているLoopStartコンポーネント です。
package com.infoteria.asteria.flowlibrary2.component.control;
import com.infoteria.asteria.flowengine2.execute.ExecuteContext;
import com.infoteria.asteria.flowlibrary2.FlowException;
import com.infoteria.asteria.flowlibrary2.component.ComponentException;
import com.infoteria.asteria.flowlibrary2.component.SimpleComponent;
import com.infoteria.asteria.flowlibrary2.stream.StreamType;
import com.infoteria.asteria.flowlibrary2.property.IntegerProperty;
public class LoopStartComponent extends SimpleComponent {
public static final String COMPONENT_NAME = "LoopStart";
public String getComponentName() { return COMPONENT_NAME;}
private static final String INVALID_LOOP_COUNT = "1";
private IntegerProperty _loopCount = new IntegerProperty("LoopCount", true, true, 1);
private int _count;
public LoopStartComponent() {
getInputConnector().setAcceptType(StreamType.ALL);
getInputConnector().setAcceptLinkCount(1);
getOutputConnector().setAcceptType(StreamType.ALL);
registProperty(_loopCount);
}
public boolean loopPossibility() {
return true;
}
public boolean execute(ExecuteContext context) throws FlowException {
_count = _loopCount.intValue();
if (_count <= 0)
throw new ComponentException(getMessage(INVALID_LOOP_COUNT, Integer.toString(_count)));
_count--;
passStream();
return _count == 0;
}
public int executeLoop(ExecuteContext context) throws FlowException {
_count--;
passStream();
return _count == 0 ? LOOP_END : LOOP_CONTINUE;
}
}
executeメソッドでプロパティに設定されたループ回数を取得してメンバー変数「_count」に設定しています。
loopPossiblityメソッドは常にtrueを返しています。
ループするコンポーネントでは定義ファイルのOutput要素に「loop="true"」という属性を付加します。
<xsc lang="ja" xmlns="http://www.infoteria.com/asteria/flowengine/definition">
<Component category="コントロール" icon="loop_n.png" name="LoopStart" toolTip="指定回数ループします">
<Class>com.infoteria.asteria.flowlibrary2.component.control.LoopStartComponent</Class>
<Message key="1">ループする回数が不正です。: %1</Message>
<Property displayName="汎用" mapping="false" name="Exception" toolTip="Exception" type="exception"/>
<Property displayName="ループする回数" mapping="true" name="LoopCount" toolTip="LoopCount" type="int">1</Property>
<Input accept="ALL"/>
<Output loop="true" streamPassThrough="true"/>
</Component>
</xsc>
こうすることでデザイナーのストリームアイコンがループを示すアイコンに変わります。
FileGetコンポーネントやRDBGetコンポーネントのようにプロパティによってループするかどうかを制御するようなコンポーネントでは、
LoopProcess型のプロパティを使用します。
分岐コンポーネントはソースコード的にはComponentExitを複数持つコンポーネントです。
Component#getStateArrayメソッドが複数のStateを返す
Component#getComponentExitメソッドがStateに対応するComponentExitを返す
execute(またはexecuteLoop)メソッド実行後にComponent#getStateメソッドが次に実行するStateを返す
つまり分岐コンポーネントを作成する場合は、上記の条件を満たすように作成しなければならないと言うことです。SimpleBranchComponent を継承して作成するのが簡単です。
分岐コンポーネントのサンプルとして一定の実行回数ごとに分岐するコンポーネントを以下に示します。
import com.infoteria.asteria.flowengine2.execute.ExecuteContext;
import com.infoteria.asteria.flowlibrary2.component.SimpleBranchComponent;
import com.infoteria.asteria.flowlibrary2.FlowException;
import com.infoteria.asteria.flowlibrary2.property.IntegerProperty;
import com.infoteria.asteria.flowlibrary2.stream.StreamDataObject;
import com.infoteria.asteria.flowlibrary2.stream.StreamType;
/**
* 実行回数が指定の回数の倍数の場合に分岐するコンポーネント
*/
public class BranchByExecCountComponent extends SimpleBranchComponent {
public static final String COMPONENT_NAME = "BranchByExecCount";
public String getComponentName() { return COMPONENT_NAME;}
private IntegerProperty _branchCountProp = new IntegerProperty("BranchCount", true, false);
public BranchByExecCountComponent() {
super(StreamType.ALL, StreamType.ALL, StreamType.ALL);
registProperty(_branchCountProp);
}
public boolean execute(ExecuteContext context) throws FlowException {
StreamDataObject is = getInputConnector().getStream();
boolean bBranch = false;
long execCount = getExecuteCount();
long branchCount = _branchCountProp.longValue();
if (execCount % branchCount == 0)
bBranch = true;
setOutputStream(bBranch, is);
return true;
}
}
SimpleBranchコンポーネントではgetStateArrayメソッドは「default」と「branch」というふたつの値を返します。
続いてこのコンポーネントの定義ファイルを以下に示します。
<xsc lang="ja" xmlns="http://www.infoteria.com/asteria/flowengine/definition">
<Component category="Sample" icon="" name="BranchByExecCount" toolTip="実行回数による分岐">
<Class>BranchByExecCountComponent</Class>
<Property displayName="汎用" mapping="false" name="Exception" toolTip="Exception" type="exception"/>
<Property displayName="分岐する実行回数" name="BranchCount" mapping="false" type="int">1000</Property>
<Input accept="ALL"/>
<Output streamPassThrough="true"/>
<Output location="right" ref="true" state="branch"/>
</Component>
</xsc>
分岐コンポーネントでは分岐に対応する数だけOutput要素を定義します。
またref属性はのコネクタの出力ストリーム定義は他のコネクタの定義を参照していることを示しています。
このコンポーネントでは、どちらの出力コネクタでも入力ストリームをそのまま出力しているので、両方のOutput要素で「streamPassThrough="true"」とすることも
できますが、その場合ストリームペインがタブ化されて出力ストリーム定義がふたつ表示されます。
一方がstreamPassThrough、他方がrefの場合
両方がstreamPassThroughの場合
どちらの定義内容であってもサーバー側のコンポーネントの動作は変わりませんが、前者の定義の方が情報量が少ない分フロー開発者に優しいと言えます。
入出力が複数あるコンポーネントとはComponentEntrance(あるいはComponentExit)にサブコネクタがあるコンポーネントのことです。
public MultiInOutComponent() {
//入力サブコネクタの作成(SimpleMailコンポーネントから抜粋)
InputConnector sub = new InputConnector(StreamType.ALL, false);
sub.setAcceptLinkCount(InputConnector.LINK_UNBOUNDED);
sub.setAcceptContainer(true);
sub.setExpandContainer(true);
getComponentEntrance().addSubConnector("Attachment", sub);
//出力サブコネクタの作成(RecordFilterコンポーネントから抜粋)
OutputConnector sub = new OutputConnector(at, false);
getComponentExit(STATE_DEFAULT).addSubConnector("Unmatch", sub);
...
}
フローを作成する場合入出力共にデフォルトコネクタにはリンクが必須ですが、サブコネクタではリンクを必須とするかどうかを指定することができます。メールコンポーネント 、RecordFilterコンポーネント ともにデフォルトではサブコネクタはアイコン上に
表示されていませんが、コンポーネントのソース側ではそれらのサブコネクタは常に存在します。(デザイナー上でサブコネクタが表示されているかどうかはコンポーネント
の動作には関係がありません。)
サブコネクタからの入力ストリームの取得や出力ストリームの設定はデフォルトコネクタの場合と同じようにexecute(またはexecuteLoop)内で行います。
サブコネクタは定義ファイルではInputまたはOutput要素の子要素にSubConnector要素として定義します。
SubConnector要素の定義内容はlocationが指定できない以外、InputまたはOutput要素と同じです。
ExcelInput/ExcelOutputコンポーネントのように設計時に動的にコネクタ数が変わるようなコンポーネントも作成可能です。
コンポーネントの作成をMultiConnectorComponentを継承して行う
MultiConnectorComponent は入出力コネクタを動的に増減するための仕組みをあらかじめ備えた抽象クラスです。
コンパイル時にはこれらのプロパティの設定値を見て自動的にコネクタが追加されます。
定義ファイルで「InputCount」または「OutputCount」プロパティをConnectionControllerで制御する
ConnectorController はプロパティ値に応じてデザイナー上でのコンポーネント表示を変更するプラグインです。
定義ファイルに以下の定義を加えれば出力数プロパティの設定値に応じて出力コネクタ数が増減することが確認できます。
<Property displayName="出力数" name="OutputCount" type="int" >1</Property>
<PropertyListener class="com.infoteria.asteria.flowbuilder2.plugin.ConnectorController" mode="output" target="OutputCount"/>
通常は出力数を示すプロパティをインスペクタ上に表示してフローの開発者に直接設定させることはあまりなく、
Excelコンポーネントのように非表示プロパティとした上で別途コンポーネントをダブルクリックした時に起動するコンポーネントエディタから制御します。
コンポーネントの実行中に何らかの例外が発生した場合はFlowException (のサブクラス)をthrowします。ComponentException またはComponentExceptionByMessageCode を作成してthrowします。
FlowExceptionのサブクラスには他にStreamで例外が発生した場合のStreamException 、Connectionで例外が発生した場合のFlowConnectionException などがあります。
コンポーネントの実行でExceptionが発生した場合、それはExceptionPropertyに設定されたエラー処理フロー、あるいは組み込みのエラー処理によって処理されます。
ExceptionPropertyでキャッチできるのはFlowExceptionだけです。
FlowExceptionにはStateというExceptionの種類を表す属性があります。特に設定しない限りStateの値はFlowException#STATE_DEFAULT(=0)という値になります。
またExceptionPropertyにもState属性があり、FlowExceptionのStateと対応しています。
SimpleComponentとSimpleBranchComponentには最初から「State=0」のExceptionPropertyが「Exception」というプロパティ名で登録されているので、
これを継承してコンポーネントを作成する限りコンポーネント開発者が自分で汎用のExceptionPropertyを追加する必要はありません。
例えばFileGetコンポーネントではファイルが見つからなかった場合には「State=1」のExceptionがthrowされます。
コンポーネントの「ファイルが存在しない」プロパティ(「State=1」のExceptionProperty)にエラー処理が設定されていればそれを実行
それがない場合に、
それもない場合に、
いずれもない場合はそこで異常終了
エラーメッセージなどのリソースはソースファイル中に直接書くことも出来ますが、定義ファイル中にMessage要素として記述することでソースと分離することができます。
<!--
Message要素で定義した内容はComponentのソースファイル中で
String filename;
String msg = getMessage("1", filename);
のようにパラメーター(%1〜%3)を置換しながら取得することができます。
-->
<Message key="1">ファイルパスが不正です : %1</Message>
ComponentExceptionByMessageCode はこのメッセージリソースの取得を簡単に行えるようにしたFlowExceptionサブクラスです。
FlowExceptionにはここまで説明してきた以外に設定可能な項目がいくつかあります。
パラメーター名と値(FlowException#addParamメソッド)
ストリーム(FlowException#setStreamメソッド)
エラーコード(FlowException#setErrorCodeメソッド)BranchByExceptionコンポーネント での分岐条件
として使用することもできます。
任意のオブジェクト(FlowException#setObjectメソッド)
また、これらの情報をいつ設定するかについて、次の二つのタイミングがあります。
Exception生成時
Component#setExceptionParamメソッドをオーバーライド
これらの機能をどのように使用するかはコンポーネント開発者の設計次第です。
トランザクション処理はTransactionインターフェースを介して行われます。
Transactionインターフェースは以下に示すようにcommitメソッドとrollbackメソッドを持つインターフェースです。
package com.infoteria.asteria.flowengine2.execute;
import com.infoteria.asteria.flowlibrary2.FlowException;
public interface Transaction {
public void commit(ExecuteContext context) throws FlowException;
public void rollback(ExecuteContext context) throws FlowException;
}
トランザクションをサポートするコンポーネントではexecute(またはexecuteLoop)メソッド内でトランザクションマネージャーに
Transactionを追加していきます。
トランザクションの実装ではTransactionインターフェースを継承したExtendedTransaction として実装することも可能です。
コールバックとしてstartメソッドとprepareメソッドが追加されている
優先順位が指定できる
リカバリー時の処理を実装できる
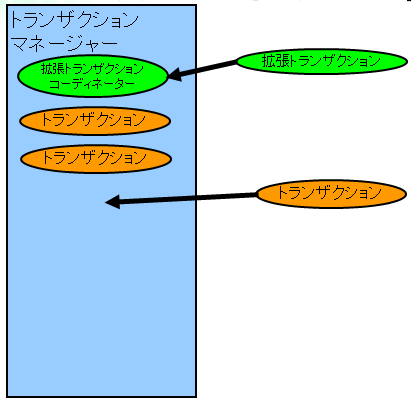
フローのトランザクションの管理はトランザクションマネージャーによって行われます。
トランザクションマネージャーへのトランザクションの追加では原則的に、追加されたトランザクションがその順番で
トランザクションマネージャー内に積み上がっていきます。
拡張トランザクションコーディネーターはそれ自体がTransactionインターフェースを実装したクラスであり、常にトランザクションマネージャー
の先頭に位置します。
拡張トランザクションコーディネーターに拡張トランザクションが追加された時にはそのstartメソッドが実行され、
積上げられたトランザクションがどういうタイミングでコミット(またはロールバック)されるかはStartコンポーネント の
トランザクション化プロパティによって決まります。
「トランザクション化=はい」の場合 トランザクションマネージャーはフローの実行終了時に、
その終了コンポーネントのトランザクションプロパティの設定にしたがって、
コミットあるいはロールバックされる。
「トランザクション化=いいえ」の場合 トランザクションマネージャーは1コンポーネント実行する度に、
毎回コミットされる。
「トランザクション化=はい」とした場合は、そこから呼び出されるサブフローやエラー処理フローでは、そのフローのStartコンポーネントの設定に
関わらずトランザクション化されます。
トランザクション化の状態によってExceptionが発生した場合のエラー処理の実行シーケンスも異なります。
「トランザクション化=はい」の場合 トランザクションマネージャーに対しては何の操作もおこなわれないままエラー処理フローが実行されます。
「トランザクション化=いいえ」の場合 トランザクションマネージャーがロールバックされてからエラー処理フローが実行されます。
エラー処理フローが設定されていない場合はいずれの場合もトランザクションマネージャーはロールバックされ、異常終了します。
トランザクションをサポートするコンポーネントを作成する場合、そのexecuteまたはexecuteLoopメソッド内でExecuteContext#addTransactionメソッドで、
作成したトランザクションをトランザクションマネージャーに積上げていきます。
この時に重要なのはトランザクションマネージャーの「同じインスタンスのトランザクションは一度しか積みあがらない」という仕様です。
/**
* Transactionとして追加されるのはComponent自身。
* つまりループの中で複数回コンポーネントが実行される場合は毎回同一インスタンスが
* ExecuteContext#addTransactionに渡される
*/
class ComponentA extends SimpleComponent implements Transaction {
public String getComponentName() { return "ComponentA";}
public boolean execute(ExecuteContext context) throws FlowException {
context.addTransaction(this);
passStream();
return;
}
public void commit(ExecuteContext context) throws FlowException {
//ExecuteContext#infoはログに情報を出力するメソッド
context.info("ComponentA commit");
}
public void rollback(ExecuteContext context) throws FlowException {
context.info("ComponentA rollback");
}
}
/**
* 追加するTransactionを毎回 new しているので常に異なるインスタンスとなる
*/
class ComponentB extends SimpleComponent {
public String getComponentName() { return "ComponentB";}
public boolean execute(ExecuteContext context) throws FlowException {
context.addTransaction(new MyTransaction());
passStream();
return;
}
private static class MyTransaction implements Transaction {
public void commit(ExecuteContext context) throws FlowException {
context.info("ComponentB commit");
}
public void rollback(ExecuteContext context) throws FlowException {
context.info("ComponentB rollback");
}
}
}
この2つのコンポーネントを用いて次のようなフローを書いたとします。
Start(トランザクション化=はい)
↓
LoopStart(ループする回数=3)
↓
ComponentA
↓
ComponentB
↓
End
するとログへの出力結果は次のようになります。
情報(End1) : ComponentA commit
情報(End1) : ComponentB commit
情報(End1) : ComponentB commit
情報(End1) : ComponentB commit
トランザクションマネージャーのコミットはフローの終了時(Endコンポーネント実行後)に一度だけ行われています。
ちなみにこのフローをStart(トランザクション化=いいえ)として実行すると、結果は以下のようになります。
情報(ComponentA1) : ComponentA commit
情報(ComponentB1) : ComponentB commit
情報(ComponentA1) : ComponentA commit
情報(ComponentB1) : ComponentB commit
情報(ComponentA1) : ComponentA commit
情報(ComponentB1) : ComponentB commit
トランザクション化=いいえの場合はコンポーネント実行直後にトランザクションマネージャーがコミットされるので、
ComponentAが2回目に実行される際には以前に追加したTransactionは残っておらず、
再度ComponentA自身がTransactionとして追加されているのです。
拡張トランザクションでは障害発生時のリカバリー処理を実装することができます。
この場合は再起動時に保存されているトランザクションステータスを元にリカバリーが実行されます。
トランザクションで使用している外部リソース(例えばDBMS)が何らかの理由で異常終了した。
この場合FSMCでの設定に従って既定の回数リトライが行われます。
いずれの場合もリカバリー時に実行されるのはRecoveryData#recovery メソッドです。
getRecoveryPolicyメソッドでRECOVERY_AVAILABLEまたはRECOVERY_REQUIREDを返す
RecoveryDataを適切に実装する
現在標準でExtendedTransactionを実装しているトランザクションはRDBに対するトランザクションのみで
リカバリー可能なExtendedTransactionはXA対応のRDBトランザクションのみです。
標準で提供されているコンポーネントでトランザクションを実装しているものには以下のようなものがあります。
コンポーネント コミット ロールバック
RDBGet DBMSをコミットする DBMSをロールバックする
FileGet 「コミット時の処理=ファイルを削除」の場合、
ファイルを削除する 何もしない
FileGet 「コミット時の処理=ファイルを削除」の場合、
ファイルを削除する 何もしない
POP3 「コミット時の処理=サーバーからメッセージを削除」の場合、
メッセージを削除する 何もしない
RDBGetやRDBPutなどのコネクションを扱うコンポーネントでは、同一コネクションを使用する場合には同じトランザクション
インスタンスを使用するので、複数のRDB系コンポーネントを配置してもトランザクション化されている場合は一連トランザクションになります。
「トランザクション」というとDBMSに対するトランザクションのイメージが強いですが、
フローサービスのトランザクションは考え方によっては実行タイミングの異なる処理を記述できる仕組みと捉えることもできます。
Connection とはコンポーネントから参照できる定義体のセットであり、またその定義情報を基に生成されるクラスをラップするクラスでもあります。
これらのコネクションにそれぞれ対応するConnectionクラスがあり、それぞれになんらかのクラスがラップされているわけですが、
現在はRDBConnection と汎用コネクション 以外のConnectionクラスの仕様は一般公開されていません。
Connectionを使用するクラスではコネクション種別を指定して、ConnectionPropertyを作成します。
ここで返されるのはコネクション種別毎に異なるConnectionインターフェースの実装クラスなので、実際のクラスにキャストして使用します。
またConnectionを使用する場合はそのTransactionオブジェクトはExecuteContext#getConnectionTransactionメソッドで取得します。
private ConnectionProperty _connectionProp = new ConnectionProperty(RDBConnectionEntry.TYPE, "Connection");
/**
* executeメソッドの先頭で使用しているConnectionに対応するTransactionを追加
*/
public boolean execute(ExecuteContext context) throws FlowException {
RDBConnection rcon = (RDBConnection)context.getConnection(_connectionProp);
java.sql.Connection con = rcon.getConnection();
...
context.addTransaction(context.getConnectionTransaction(_connectionProp));
}
*/
JDBCのConnectionを取得した後はそれを使用して自由にJDBCのプログラミングを行って構いませんが、Connection#closeメソッドを実行してはいけません。
また、Connection#commit/Connection#rollbackメソッドも実行してはいけません。これらはフローのトランザクションフレームワークの中で実行されるべきメソッドだからです。
ストリーム作成とコネクション使用の例として指定のテーブルの列情報を出力するコンポーネントの例を以下に示します。
import com.infoteria.asteria.flowengine2.execute.ExecuteContext;
import com.infoteria.asteria.flowengine2.flow.InputConnector;
import com.infoteria.asteria.flowlibrary2.FlowException;
import com.infoteria.asteria.flowlibrary2.component.SimpleComponent;
import com.infoteria.asteria.flowlibrary2.component.ComponentException;
import com.infoteria.asteria.flowlibrary2.stream.*;
import com.infoteria.asteria.flowlibrary2.property.*;
import com.infoteria.asteria.connection.RDBConnection;
import com.infoteria.asteria.connection.RDBConnectionEntry;
import com.infoteria.asteria.value.Value;
import java.sql.*;
import java.util.ArrayList;
/**
* 指定のTableのカラム情報をCSVまたはRecord型の出力ストリームとして出力するコンポーネント<br/>
* コンポーネント内での作成するストリームのフィールド数は固定(カラム名、データ型の2列)<br/>
* なので定義ファイル側でフィールド定義を固定しておく<br/>
* Tableが見つからない場合のExceptionは通常のExceptionとは別に「TableNotFoundException」という
* プロパティでキャッチできることとする。
*/
public class TableInfoComponent extends SimpleComponent {
public static final String COMPONENT_NAME = "TableInfo";
public String getComponentName() { return COMPONENT_NAME;}
private static final int TABLE_NOT_FOUND = 1;
/**
* このコンポーネントが宣言されているmscファイルに
<Message key="1">テーブルが見つかりません: %1</Message>
<Message key="2">出力ストリームのフィールド定義が不正です</Message>
というエントリを追加すること
*/
private static final String MSG_TABLE_NOT_FOUND = "1";
private static final String MSG_INVALID_FIELDDEF = "2";
private ConnectionProperty propConnection = new ConnectionProperty(RDBConnectionEntry.TYPE, "Connection");
private StringProperty propTableName = new StringProperty("TableName", true, true);
private ExceptionProperty propTableNotFound = new ExceptionProperty("TableNotFoundException", TABLE_NOT_FOUND);//第2引数には0以外の任意の数値を指定
private RDBConnection _rcon = null;
public TableInfoComponent() {
//入力ストリームは使用しないので、すべてのストリームフォーマットを複数受け入れ可能とする
//FileSystem(Get)などの入力ストリームを使用しない標準コンポーネントはすべてこのようにデザインされている
getInputConnector().setAcceptLinkCount(InputConnector.LINK_UNBOUNDED);
//getInputConnector().setAcceptContainer(true);
//getInputConnector().setExpandContainer(false);
getInputConnector().setAcceptType(StreamType.ALL);
//出力ストリームはCSVまたはRecord
getOutputConnector().setAcceptType(StreamType.CSV|StreamType.RECORDS);
//プロパティの登録
registProperty(propConnection);
registProperty(propTableName);
registProperty(propTableNotFound);
//「Exception」という名前のExceptionPropertyはSimpleComponentクラスでregistされている。
}
/** コンポーネント初期化時にRDBConnectionを取得 */
public void init(ExecuteContext context) throws FlowException {
_rcon = (RDBConnection)context.getConnection(propConnection);
//propConnectionで指定されたConnectionが取得できない場合はここでFlowConnectionException( extends FlowException)が発生する
//必要ならそのExceptionは「Exception」プロパティで指定したフローによってキャッチする。
}
public void term(ExecuteContext context) {
_rcon = null;
//現状ではこの処理は必須ではないができるだけインスタンス変数は初期状態に戻すことが望ましい。
}
public boolean execute(ExecuteContext context) throws FlowException {
Connection con = _rcon.getConnection();
String table = propTableName.strValue();
try {
//DatabaseMetaDataを使用してテーブル情報を取得しても良いが、ここではResultSetMetaDataからTable情報
//を取得することにした。
Statement stmt = con.createStatement();
ResultSet rs = null;
try {
String sql = "SELECT * FROM " + table + " WHERE 1 = 2";
rs = stmt.executeQuery(sql);
} catch (SQLException e) {
//ここでキャッチされた例外はテーブルが見つからなかった場合と思われる。
//ここでthrowするExceptionだけStateを「1」に。
throw new ComponentException(getMessage(MSG_TABLE_NOT_FOUND, table), TABLE_NOT_FOUND);
}
ResultSetMetaData meta = rs.getMetaData();
StreamFactory factory = getOutputConnector().getStreamFactory();
//定義されたフィールド数が2列でなければExceptionとする。
if (factory.getFieldDefinition().getFieldCount() != 2)
throw new ComponentException(getMessage(MSG_INVALID_FIELDDEF));
StreamDataObject os = null;
switch (factory.getType()) {
case StreamType.CSV: os = createCSV(meta); break;
case StreamType.RECORDS: os = createRecord(meta); break;
default:
//このコードが実行されることはない
throw new IllegalStateException();
}
setOutputStream(os);
//使用したコネクションをTransactionManagerに追加する
context.addTransaction(context.getConnectionTransaction(propConnection));
} catch (SQLException e) {
throw new ComponentException(e);
}
return true;
}
/** CSVストリームの作成 */
private StreamDataObject createCSV(ResultSetMetaData meta) throws FlowException, SQLException {
int len = meta.getColumnCount();
//CSV文字列の作成
StringBuffer buf = new StringBuffer(512);
for (int i=1; i<=len; i++) {
buf.append(meta.getColumnName(i)).append(',');
buf.append(meta.getColumnTypeName(i)).append('\n');
}
StreamFactoryCSV factory = (StreamFactoryCSV)getOutputConnector().getStreamFactory();
return factory.create(buf.toString());
}
/** Recordストリームの作成 */
private StreamDataObject createRecord(ResultSetMetaData meta) throws FlowException, SQLException {
int len = meta.getColumnCount();
//Record用のListの作成
ArrayList list = new ArrayList(len);
for (int i=1; i<=len; i++) {
Value[] values = new Value[2];
values[0] = new Value(meta.getColumnName(i));
values[1] = new Value(meta.getColumnTypeName(i));
list.add(values);
}
StreamFactoryRecord factory = (StreamFactoryRecord)getOutputConnector().getStreamFactory();
return factory.create(list);
}
/** ExceptionParamとして「TableName」を設定 */
public void setExceptionParam(FlowException e) {
e.addParam(propTableName.getName(), propTableName.getValue());
}
}
汎用コネクションは任意の名前と値のセットをコネクション定義として保存しておける仕組みです。
private ConnectionProperty _connectionProp = new ConnectionProperty(CommonConnectionEntry.TYPE, "Connection");
public boolean execute(ExecuteContext context) throws FlowException {
CommonConnection con = (CommonConnection)context.getConnection(_connectionProp);
MyObject obj = (MyObject)con.getRelatedObject();
if (obj == null) {
obj = createObject((CommonConnectionEntry)con.getEntry());
con.setRelatedObject(obj);
}
//ToDo ここでMyObjectを使用した処理を実装
return true;
}
private MyObject createObject(CommonConnectionEntry entry) {
//コネクション定義で設定したパラメーターの取得
Map map = entry.getParameterMap();
String value1 = (String)map.get("AAA");
String value2 = (String)map.get("BBB");
//取得したパラメーターを利用してオブジェクトを生成
return new MyObject(value1, value2);
}
実行中にExecuteContextから同じ名前で取得されるConnectionは常に同一インスタンスです。
またコネクション定義でコネクションプールを設定しておけば生成したオブジェクトを一定期間プールしておくことも可能です。Closable インターフェースを実装しておけば、プールから解放されるタイミング
で実行されるコールバックを実装することができます。
pluginCallメソッドはデザイナーで作成したプラグインからのリクエストを受けて実行されるコールバックメソッドです。
また、pluginCallでStringの配列を返すレスポンスを作成しておけばそのString配列はデザイナー側でpluginCallPropertyを定義することに
よりドロップダウンリスト形式のプロパティにすることができます。
pluginCallの詳細についてはプラグイン開発者ガイド を参照してください。
IndependentMapとはExecuteContext#getIndependentMapメソッドで取得できるMapのことです。
このMapを利用することで関連する複数のコンポーネントで任意のオブジェクトを共有することができます。
Mapのキーに使用する名前には厳密なルールはありませんが、重複を避けるためにJavaのパッケージ名と同様にドメイン名を
付加した名前を使用することを推奨します。
private MyObject _obj = null;
//このコンポーネントがフローの中で最初に使用された場合だけMyObjectを生成し、
//後のコンポーネントではそれを使いまわす
public void init(ExecuteContext context) throws FlowException {
String key = getClass().getName();
_obj = (MyObject)context.getIndependentMap().get(key);
if (_obj == null) {
_obj = createMyObject();
context.getIndependentMap().put(key, _obj);
}
}
サブフローやエラー処理フロー、Nextフローを含む一連のフローはひとつのスレッドで実行されるので、
上のコードではマルチスレッドについて考慮する必要はありません。
IndependentMapにputされたオブジェクトがReleasable インターフェースを実装していた場合は、
リクエスト終了時にそのreleaseメソッドがコールバックされます。
package com.infoteria.asteria.flowengine2.execute;
/**
* リソース開放のためのインターフェース。
例えば先にあげた特殊なDBMSの接続情報をIndependentMapに入れて使いまわすなら、そのクローズは
リクエスト終了時が適切なのでこのインターフェースを実装するようにしてください。
コンポーネントのexecute(またはexecuteLoop)の処理がある程度時間がかかることが予想される場合、
強制終了に対処するためのコードを実装することが望ましいです。
例として次のようなコンポーネントの実行処理を考えます。
RDBのテーブルに対してUpdate文を発行するコンポーネント
更新内容は入力レコードに設定されているものとし、レコードが複数ある場合はその数だけループでUpdate文を実行する
この処理の実装イメージを以下に示します。
import javax.sql.PreparedStatement;
...
/**
* 入力レコードでループを回し処理を順次実行する
*/
public boolean execute(ExecuteContext context) throws FlowException {
PreparedStatement stmt = getStatement();
Record record = getInputConnector().getStream().getRecord();
while (record != null) {
doUpdate(stmt, record);
record = record.nextRecord();
}
passStream();
return true;
}
/**
* 更新用のSQLを生成する
*/
private PreparedStatement getStatement() {
...
}
/**
* DBに対してUpdateを実行する
*/
private void doUpdate(PreparedStatement stmt, Record record) {
...
}
この処理の場合executeメソッドの実行開始から終了までに時間のかかる要因として次の2つが考えられます。
入力レコードの数が多い
更新対象の行がロックされている可能性がある
次節以降これらの場合に適切に強制終了が実行される方法を説明ます。
ExecuteContext#notifyRunningはフローの実行エンジンに対して処理の実行中であることを通知するためのメソッドです。
/**
* 入力レコードでループを回し処理を順次実行する
*/
public boolean execute(ExecuteContext context) throws FlowException {
PreparedStatement stmt = getStatement();
Record record = getInputConnector().getStream().getRecord();
while (record != null) {
doUpdate(stmt, record);
record = record.nextRecord();
context.notifyRunning();
}
passStream();
return true;
}
cancelメソッドは強制終了時に指定のタイムアウト時間(デフォルト5秒)待ってもコンポーネントの実行が終わらなかった場合に
実行されるメソッドです。
この例の場合、テーブルに対してロックがかかっているとJDBCのPreparedStatement#executeUpdateメソッドで処理が停滞し
いつまでたっても処理が終わりませんが、キャンセル時にPreparedStatment#cancelメソッドを実行することでSQLの実行を中断
させることができます。
private PreparedStatement _stmt = null; //cancelメソッドからアクセスできるようにメンバ変数にする
/**
* 入力レコードでループを回し処理を順次実行する
*/
public boolean execute(ExecuteContext context) throws FlowException {
_stmt = getStatement();
try {
Record record = getInputConnector().getStream().getRecord();
while (record != null) {
doUpdate(_stmt, record);
record = record.nextRecord();
context.notifyRunning();
}
} finally {
_stmt = null;
}
passStream();
return true;
}
/**
* cancelメソッドの実装
*/
public boolean cancel() {
if (_stmt != null) {
try {
_stmt.cancel();
} catch (SQLException e) {
} catch (NullPointerException e) {
}
}
return true;
}
cancelメソッド内で_stmtに対するnullチェックを行っているにも関わらずNullPointerExceptionをキャッチしていることに注意してください。別スレッド から実行されます。
このようにcancelメソッドの実装は否応なくマルチスレッドプログラミングになるのでシングルスレッドでの
処理のみを考えれば良いexecuteなどの実装とはやや性質が異なります。
Component#internalInitはコンポーネントの初期化時に一度だけ実行されるメソッドです。
例えばMutexコンポーネント はその初期化時にflow-ctrlにMutex関連のコマンドを追加しています。
Componentクラスにはサーバー終了時に実行されるコールバックメソッドはありません。Finalizer インターフェースを実装したクラスを
作成し、FlowEngine#addFinalizerメソッドで直接FlowEngineに登録してください。
package com.infoteria.asteria.flowengine2.execute;
/**
* サーバー終了時に実行されるコールバックのためのインターフェース。
Finalizerインターフェースは正常終了時の実行シーケンスの中で実行されるコールバックなので、
フローサービス自体が異常終了した場合は実行されません。
コンポーネントでライセンスチェックを行いたい場合は、ライセンスチェックに必要な情報、
例えばライセンスファイルはコンポーネントのjarファイルと同じ場所に置くことを推奨します。
[data dir]/system/lib/components
に配置しますので、ライセンスファイルも同じフォルダーに配置します。
実際のライセンスチェックの処理は、Component#checkLicenseをオーバーライドして実装します。
/** ライセンスチェック処理を記述します */
public void checkLicense() throws LicenseException {
}
このメソッドの中でComponent#getComponentLibPathメソッドを実行すると前述のcomponentsフォルダーのパスを取得できます。
これにより、同じフォルダーに配置したライセンスファイルを取得することができます。
ライセンスチェックの基本的な実装は次のようになります。
public void checkLicense() throws LicenseException {
// ライセンスファイルを取得します
File licenseFile = new File(getComponentLibPath(), "ライセンスファイル名");
// licenseFileを読み込んでライセンスチェックを行います
// ライセンス違反の場合にはLicenseExceptionをthrowします
if (licenseError) {
throw new LicenseException();
}
}
どのような方法でライセンスチェックをする場合でも、ライセンス違反となった場合にはLicenseExceptionをthrowするようにしてください。
ComponentCompilerはその名の通りコンポーネントのコンパイラです。
コンポーネントのコンパイル時の流れは以下のようになります。
ComponentManagerよりコンポーネントのインスタンスを取得
Component#getCompilerメソッドによりComponentCompiler を取得
ComponentCompilerにComponent要素を渡してコンパイル
つまりComponent#getCompilerメソッドをオーバーライドし、自作のComponentCompilerサブクラスを返すようにすることで
コンパイラの動作を拡張することができます。
プロパティ値の整合性のチェック
プロパティ間の整合性のチェック
コンパイル時に1度だけ行えば良い処理の実行WebServiceコンポーネント はWSDLファイルのパースを実行時に行い、それをComponentのメンバー変数に設定しています。
フローデザイナーのプラグインによって作成されたプロパティのコンパイル
動的なコネクタの増減
ほとんどの場合はComponentCompilerのサブクラス化でオーバーライドしなければならないのはpostCompile(Map)メソッドだけです。
ComponentCompilerは独立クラスとして作成することも可能ですが、Componentのprivate classとして作成する方が
プロパティ値やメンバー変数へのアクセスが簡単になり便利です。
フローの実行時にはコンパイルされたComponentがそのまま使用されるのではなく複製されます。
複製の際に使用されるメソッドはcloneメソッドですが、Componentのcloneメソッドの実装は通常のJavaの
Cloneableによる実装とは異なりClass#newInstanceメソッドを用いて実装されています。
以下にComponentクラスのcloneメソッドの実装の一部を以下に示します。
public Object clone() {
Component ret = null;
try {
ret = (Component)getClass().newInstance();
} catch (IllegalAccessException e) {
} catch (InstantiationException e) {
}
ret.setName(getName());
int cnt = ret.getPropertyCount();
for (int i=0; i < cnt; i++) {
Property prop = ret.getProperty(i);
prop.assign(getProperty(i));
}
...
return ret;
}
何故このような実装になっているかと言うと複製を作成する際にもComponentのコンストラクタを動かしたいからです。
拡張コンパイラを使用してコンパイル時にインスタンス変数に何らかの値を設定した場合はComponent#clone
メソッドをオーバーライドして、そのコピーを自分で行う必要があります。
フロー内の各コンポーネントのインスタンスが別になっているため、通常コンポーネント開発者は
スレッドセーフについてほとんど考える必要がありませんが、コンパイラ拡張によってメンバー変数でオブジェクトを
共有する場合はそのスレッドセーフ性についてはコンポーネント開発者が担保しなければなりません。
SDKで新たに公開されたIndependentMapやComponentCompilerを用いたサンプルとしてフローの同時起動数を制限する
コンポーネントのソースを以下に示します。
package com.infoteria.sample.component;
import com.infoteria.asteria.flowengine2.FlowEngine;
import com.infoteria.asteria.flowengine2.execute.ExecuteContext;
import com.infoteria.asteria.flowengine2.execute.Finalizer;
import com.infoteria.asteria.flowengine2.execute.Releasable;
import com.infoteria.asteria.flowengine2.flow.Component;
import com.infoteria.asteria.flowengine2.flow.ComponentCompiler;
import com.infoteria.asteria.flowlibrary2.component.ComponentExceptionByMessageCode;
import com.infoteria.asteria.flowlibrary2.component.SimpleComponent;
import com.infoteria.asteria.flowlibrary2.FlowException;
import com.infoteria.asteria.flowlibrary2.property.ExceptionProperty;
import com.infoteria.asteria.flowlibrary2.property.IntegerProperty;
import com.infoteria.asteria.flowlibrary2.property.StringProperty;
import com.infoteria.asteria.flowlibrary2.stream.StreamType;
import java.util.Map;
import java.util.HashMap;
/**
* フローの同時実行数を制御するコンポーネント<br/>
* 同じIDを持つフローを同時に指定の個数までしか実行できなくする
*/
public class ThreadControlComponent extends SimpleComponent
{
private static ThreadControl __control;
private static final String COMPONENT_DUPLICATE = "1";
private static final String LIMIT_OVER = "2";
private static final String INVALID_LIMIT = "3";
private static final String CURRENT_COUNT = "4";
private static final int STATE_LIMIT_OVER = 1;
public static final String COMPONENT_NAME = "ThreadControl";
public String getComponentName() { return COMPONENT_NAME;}
private StringProperty _idProp = new StringProperty("ID", false, false);
private IntegerProperty _limitProp = new IntegerProperty("Limit", true, false, 1);
private ExceptionProperty _limitOverProp = new ExceptionProperty("LimitOverException");
public ThreadControlComponent() {
super(StreamType.ALL, StreamType.ALL);
registProperty(_idProp);
registProperty(_limitProp);
registProperty(_limitOverProp);
}
public boolean execute(ExecuteContext context) throws FlowException {
//ThreadControlのID
String id = _idProp.strValue();
if (id.length() == 0)
id = getOwnerFlow().getFullName();
int limit = _limitProp.intValue();
//IndependentMapのキー
String key = getClass().getName();
ThreadControlDecrement dec = (ThreadControlDecrement)context.getIndependentMap().get(key);
if (dec != null)
throw new ComponentExceptionByMessageCode(this, COMPONENT_DUPLICATE);//このコンポーネントはリクエスト中に複数配置できません
int n = __control.inc(id, limit);
if (n < 0)
throw new ComponentExceptionByMessageCode(this, LIMIT_OVER, STATE_LIMIT_OVER);//同時起動数をオーバーしました
context.info(getMessage(CURRENT_COUNT, Integer.valueOf(n)));
context.getIndependentMap().put(key, new ThreadControlDecrement(id));
passStream();
return true;
}
/**
* コンパイル時にLimitプロパティの値をチェックして0以下ならばエラーとする
*/
protected ComponentCompiler getCompiler() {
return new MyCompiler(this);
}
private class MyCompiler extends ComponentCompiler {
public MyCompiler(Component c) {
super(c);
}
protected void postCompile(Map componentMap) {
int limit = _limitProp.intValue();
if (limit <= 0) {
String msg = getMessage(INVALID_LIMIT);
onComponentError(msg);
}
}
}
//初期化時にstaticなThreadControlオブジェクトを作成しFinalizerとして登録
public void internalInit() {
__control = new ThreadControl();
FlowEngine.addFinalizer(__control);
}
private static class ThreadControl implements Finalizer {
private Map _map = new HashMap();
public synchronized int inc(String id, int limit) {
Integer n = (Integer)_map.get(id);
if (n == null) {
_map.put(id, Integer.valueOf(1));
return 1;
}
if (n.intValue() >= limit)
return -1;
n = Integer.valueOf(n.intValue() + 1);
_map.put(id, n);
return n.intValue();
}
public synchronized int dec(String id) {
Integer n = (Integer)_map.get(id);
if (n == null)
return 0;
if (n.intValue() == 1)
_map.remove(id);
else
_map.put(id, Integer.valueOf(n.intValue() - 1));
return n.intValue() - 1;
}
/** Finalizerインターフェース */
public synchronized void release() {
_map.clear();
}
}
private class ThreadControlDecrement implements Releasable {
private String _id;
public ThreadControlDecrement(String id) {
_id = id;
}
public void release(ExecuteContext context) {
int n = __control.dec(_id);
if (context.isDebugInfoEnabled()) {
String msg = getMessage(CURRENT_COUNT, Integer.valueOf(n));
context.debugInfo(msg);
}
}
}
}
ComponentInvoker は既存のコンポーネントを独自コンポーネント内部から実行するためのユーティリティクラスです。
ただし、実行可能なのは単純なProperty/SimpleCategoryPropertyのみから構成されているコンポーネントのみであり、
拡張コンパイラによってコンパイル時に特別な処理を行っているコンポーネントは実行することができません。
以下にHttpGetコンポーネント、RDBGetコンポーネント、SimpleMailコンポーネントをComponentInvokerで実行するサンプルを示します。
//HttpGetコンポーネントの実行
import com.infoteria.asteria.flowengine2.FlowEngine;
import com.infoteria.asteria.flowengine2.execute.ComponentInvoker;
import com.infoteria.asteria.flowengine2.flow.Component;
import com.infoteria.asteria.flowlibrary2.stream.StreamFactory;
import com.infoteria.asteria.flowlibrary2.stream.StreamType;
String url = "http://www.yahoo.co.jp/";
Component c = FlowEngine.getComponentManager().getComponentInstance("HTTP(Get)");
ComponentInvoker invoker = new ComponentInvoker(c);
invoker.setPropertyBoolean("UseConnection", false);
invoker.setPropertyString("URL", url);
StreamFactory sf = StreamFactory.getInstance(StreamType.MIME);
invoker.setStreamFactory(sf);
return invoker.execute(context, component.getInputConnector().getStream());
//RDBGetコンポーネントの実行
import com.infoteria.asteria.flowengine2.FlowEngine;
import com.infoteria.asteria.flowengine2.execute.ComponentInvoker;
import com.infoteria.asteria.flowengine2.flow.Component;
import com.infoteria.asteria.flowlibrary2.stream.StreamFactory;
import com.infoteria.asteria.flowlibrary2.stream.StreamType;
import com.infoteria.asteria.flowlibrary2.stream.FieldDefinitionBuilder;
import com.infoteria.asteria.flowlibrary2.stream.FieldType;
import com.infoteria.asteria.value.Value;
String connection = "RDB1";
String sql = "SELECT COL1, COL2, COL3 FROM TABLE1 WHERE COL1 = ?p1?";
Component c = FlowEngine.getComponentManager().getComponentInstance("RDB(Get)");
ComponentInvoker invoker = new ComponentInvoker(c);
invoker.setPropertyString("Connection", connection);
invoker.setPropertyString("SQL", sql);
invoker.setCategory("SQLParameter", "p1", new Value("ABC"));
StreamFactory sf = StreamFactory.getInstance(StreamType.RECORDS);
FieldDefinitionBuilder builder = new FieldDefinitionBuilder();
builder.addField("field1", FieldType.STRING);
builder.addField("field2", FieldType.STRING);
builder.addField("field3", FieldType.STRING);
sf.setFieldDefinition(builder.getDefinition());
invoker.setStreamFactory(sf);
return invoker.execute(context, component.getInputConnector().getStream());
//SimpleMailコンポーネントの実行
import com.infoteria.asteria.flowengine2.FlowEngine;
import com.infoteria.asteria.flowengine2.execute.ComponentInvoker;
import com.infoteria.asteria.flowengine2.flow.Component;
import com.infoteria.asteria.flowlibrary2.stream.StreamFactory;
import com.infoteria.asteria.flowlibrary2.stream.StreamType;
import com.infoteria.asteria.flowlibrary2.stream.FieldDefinitionBuilder;
import com.infoteria.asteria.flowlibrary2.stream.FieldType;
import com.infoteria.asteria.value.Value;
String connection = "smtp1";
String from = "user1@xxxx.co.jp";
String to = "user1@xxxx.co.jp";
String subject = "てすと";
Component c = FlowEngine.getComponentManager().getComponentInstance("SimpleMail");
ComponentInvoker invoker = new ComponentInvoker(c);
invoker.setPropertyString("Connection", connection);
invoker.setPropertyString("From", from);
invoker.setPropertyString("To", to);
invoker.setPropertyString("Subject", subject);
return invoker.execute(context, component.getInputConnector().getStream());
上記のサンプルでは単純に1コンポーネントを実行してその出力ストリームを返しているだけですが、この技術を使用すれば複数のコンポーネントの実行を組み合わせたものを
1コンポーネントにまとめることも可能です。
サンプルコードで概ねやっていることはわかると思いますが、実際のところはComponentInvokerを使用するためには
実行対象のコンポーネントについてプロパティ名などの内部仕様まで知っている必要があります。(必要な情報はほとんどコンポーネント定義ファイル(xscファイル)より得ることができます。)
将来のバージョンでの仕様変更によって実行しているコンポーネントが拡張コンパイラを必要とする形に変更される可能性も0ではありません。
その他サンプルとして標準で提供されているコンポーネントのいくつかのソースを公開します。