 GoogleBigQueryGet - GoogleBigQueryからの入力
GoogleBigQueryGet - GoogleBigQueryからの入力
GoogleBigQueryへSELECT文を発行して結果セットをストリームとして出力します。
GoogleBigQueryへのアクセスはCData Software Inc.社の提供する技術を利用してRDBのようにSQLでアクセスする手段を提供します。利用できるSQLなどの詳細についてはこちらも参考にしてください。
ストリーム情報
| 入力 | フォーマット | すべて |
|---|---|---|
| 接続数 | 無制限 | |
| 説明 |
入力ストリームは使用せず、すべて無視します。 | |
| 出力 | フォーマット | Record |
コンポーネントプロパティ
| 名前 | データ型 | マッピング | 説明 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| コネクション名 | connection | - | 接続先のGoogleBigQueryを指定します。 コネクションペインまたは管理コンソールにて作成されたGoogleBigQuery接続名を選択します。 | ||||||
| SQL文 | string | In & Out |
実際にGoogleBigQueryに対して発行されるSQLを指定します。 SQLビルダーによって自動作成したり、さらに編集したりすることができます。詳細については下記トピック「SQLビルダーの使い方」を参照してください。SQLビルダーを使わずに、前に連結したマッパーからSQL文の文字列をマッピングすることもできます。 | ||||||
| フィルターを指定 | boolean | - |
取得した結果セットに対して読込み開始行と取出す件数でフィルタリングを行うかどうかを指定します。
| ||||||
| 読込み開始行 | int | In & Out | フィルターを指定が「はい」の場合に出力するレコードの開始行を指定します。 行のインデックスは1ベースのインデックスです。 読込み開始行が結果セットの件数よりも大きい場合はレコードが無いが発生します。(レコードが無い場合エラーが「いいえ」の場合は空の結果セットが出力されます。) | ||||||
| 取出す件数 | int | In & Out | フィルターを指定が「はい」の場合に出力するレコードの行数を指定します。 例えば読込み開始行=11、取出す件数=10の場合は入力レコードセットの11行目から10行が出力されます。 取出す件数に達する前に入力レコードが最終行に達した場合はそこまでのレコードが出力されます。 取出す件数が0の場合は、読込み開始行以降のすべての行が出力されます。 | ||||||
| タイムアウト(秒) | int | In & Out |
GoogleBigQueryへSELECT文を発行してから結果が返ってくるまでの待ち時間を秒単位で指定します。 指定時間を経過しても実行が終わらない場合は汎用となります。 0の場合はタイムアウトすることはありません。 | ||||||
| ループを開始 | loopProcess | - |
結果セットをまとめて出力するかループ時に取出す件数での指定行数ずつループして出力するかを選択します。
| ||||||
| ループ時に取出す件数 | int | In & Out | ループを開始がはいの場合に一度の実行で出力する行数を指定します。 | ||||||
| レコードが無い場合エラー | boolean | - |
結果セットのレコード件数が0件だった場合にエラーを発生するかどうかを選択します。
| ||||||
| トランザクションに含める | boolean | - |
このプロパティの値は無視されます。
| ||||||
| フェッチサイズ | int | - |
JDBCのsetFetchSize()に設定する値を指定します。 | ||||||
| SQLパラメーターを使用する | boolean | - |
$,? をSQL文で使用したいときにこのプロパティを「いいえ」にするとSQLパラメーター置換処理をせずコンポーネントを実行できます。
また、この場合はSQLパラメーターが設定されていても無視されるので注意してください。
| ||||||
| SQLパラメーター | category | In & Out | SQL文中にパラメーター書式を埋め込むことにより、SQLパラメーターの値をパラメーターまたは置換文字列として使用することができます。 SQLパラメーターはSQLビルダーを使って定義します。詳細については下記トピック「SQLビルダーの使い方」を参照してください。 |
ループ処理
ループを開始が「はい」の場合、このコンポーネントがループの起点となって結果セットのレコードを1レコードずつ出力します。
エラー処理
| タイプ | パラメータ | エラー処理フローへのストリーム | エラー コード | 説明 |
|---|---|---|---|---|
| 汎用 | なし | コンポーネントの入力ストリーム | 例外コード | SQL文が不正な場合 |
| なし | コネクション名に指定したコネクションが見つからない場合 | |||
| 例外コード | SQL文がタイムアウトした場合 | |||
| 接続エラー | なし | コンポーネントの入力ストリーム | なし | GoogleBigQueryとの接続に失敗した場合 |
| レコードが無い | なし | コンポーネントの入力ストリーム | 3 | レコードが無い場合エラーが「はい」の場合で、レコードが0件の場合 |
| 4 | レコードが無い場合エラーが「はい」の場合で、フィルターを指定を適用した結果出力レコードが0件になった場合 |
フローの強制終了
フローを強制終了すると、通常は実行中のコンポーネントの処理が終了してから次のコンポーネントに制御が遷移する時点でフローがアボートしますが、本コンポーネントでは実行中の処理を強制的に終了してフローがアボートします。
SELECT文中のカラムと出力ストリームのフィールドの関係
SQLビルダーを終了後、「フィールド定義を更新しますか?」メッセージダイアログボックスが表示されます。「はい」をクリックすると、SQLビルダーで選択したSELECT文中のカラムがストリームペインで出力ストリームとして定義されます。「いいえ」をクリックすると、ストリームペインには定義されません。
本コンポーネントの出力ストリームとしてレコードを取得するには、ストリームペインにフィールドを定義する必要がありますが、SQLビルダーで生成したSELECT文中の各カラムと出力ストリームのフィールドは順序によってマッピングされるため、カラム名とフィールド名は一致する必要はありません。
SELECTされたカラム数が出力ストリームで定義されたフィールド数と異なる場合や、カラムのデータ型が対応するフィールドのデータ型と異なる場合でも、順序によってマッピングされます。
SQLビルダーの使い方
SQLビルダーは、SQL文を自動生成する専用ツールです。SQLビルダーを使うと、簡単な操作で以下のようなことができます。
- GoogleBigQueryから取得したテーブル一覧から読み込むテーブル、フィールドを指定
- フィールドに条件やソート順を指定
- フィールドに任意の条件を指定
- パラメーターを定義して、フロー実行時の動的な値を使うSQL文を生成(SQLパラメーター)
- SQLビルダーで自動生成したSQL文を直接編集したSQL文を実行
- テスト機能を使って、実際にSQL文を発行して結果を確認
●SQLビルダーを起動する
以下のいずれかの操作でSQLビルダーを起動します。
- GoogleBigQueryGetコンポーネントをダブルクリック
- GoogleBigQueryGetコンポーネントを右クリックして表示されるメニューから「SQLビルダー」をクリック
●SQLビルダーの画面
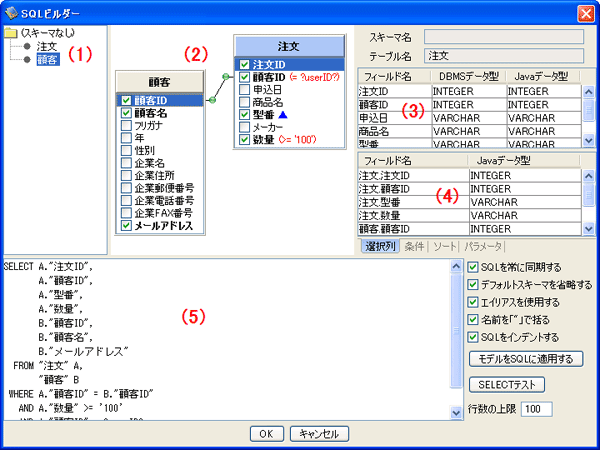
- (1)画面左:テーブル一覧を表示する領域
- (2)画面中央:テーブルを表現したリストボックスが配置される領域
- (3)画面右上部:GoogleBigQueryの詳細情報を表示する領域
- (4)画面右下部:実際に読み込むフィールドや読み込み条件を指定する領域
- (5)画面下部:自動生成されるSQL文を表示、編集する領域
●読み込むテーブルを指定する
SQLビルダーを起動すると(1)にテーブルの一覧が表示されます。読み込むテーブルを指定するには、2つの方法があります。以下の方法で操作すると、(2)にテーブルのフィールド一覧が表示されます。
ドラッグ&ドロップ
(1)の一覧からテーブル名をクリックしてドラッグを開始し、(2)にドロップします。
メニューから
(2)の空いたスペースで右クリックして表示されるメニューから「テーブル名を指定して追加」をクリックします。表示されたダイアログでテーブル名を入力して「OK」をクリックします。
- テーブルを削除する
(2)のフィールドリストで右クリックして表示されるメニューから「テーブルを削除」をクリックします。
●GoogleBigQueryの詳細情報を表示する
(1)または(2)に表示したテーブルをクリックすると、(3)に詳細情報が表示されます。
●実際に読み込むフィールドを指定する(SELECT)
実際に読み込むフィールドを指定するには、2つの方法があります。以下の方法で操作すると、(5)にSQL文が表示されます。
(2)の画面から
フィールドリストでフィールド名の左にあるチェックボックスをオンにします。(4)の選択列タブに表示されます。指定したフィールドを取り消すには、チェックボックスをオフにします。(4)の選択列タブから削除されます。
- テーブル全体を読み込む
フィールドリストでフィールドをクリックし、右クリックして表示されるメニューから「全選択」をクリックします。
全選択を取り消すには、右クリックして表示されるメニューから「全選択解除」をクリックします。
(4)の画面から(選択列タブ)
フィールド名の空いたフィールドをクリックして表示されるプルダウンリストから読み込むフィールドを選択します。
●読み込む指定をしたフィールドを編集する
(4)でフィールドをクリックしてから、右クリックして表示されるメニューから「上に移動」「下に移動」「削除」を操作します。
●重複を抑制する(DISTINCT)
(2)の画面で右クリックして表示されるメニューから「重複の抑制(DISTINCT)」を実行すると自動生成されるSELECT文にDISTINCT句が付加されます。
●レコードの並び替え(ORDER BY)
レコードを昇順または降順にソートして読み込むには、以下の2つの方法があります。以下の方法で操作すると、(5)のSQL文に反映されます。
(2)の画面から
フィールドリストでフィールドをクリックし、右クリックして表示されるメニューの「ソートに追加」から「昇順」または「降順」をクリックします。
(4)の画面から(ソートタブ)
フィールド名の空いたフィールドをクリックして表示されるプルダウンリストから並び替えのキーとなるフィールドを選択します。指定したフィールド名のソート順プルダウンリストから「昇順」または「降順」を選択します。
レコードの並び替えを取り消す
フィールドリストでフィールドをクリックし、右クリックして表示されるメニューの「ソートに追加」から「(なし)」をクリックします。
またはソートタブのフィールドをクリックし、右クリックして表示されるメニューから「削除」をクリックします。
●集約関数の使用(GROUP BY)
フィールドに対して集約関数を適用する場合には、以下の2つの方法があります。以下の方法で操作すると、(5)のSQL文に反映されます。
(2)の画面から
フィールドリストでフィールドをクリックし、右クリックして表示されるメニューから「集約関数」を経由して適用する集約関数を選択します。
(4)の画面から(集約関数タブ)
フィールド名の空いたフィールドをクリックして表示されるプルダウンリストから集約関数を適用するフィールドを選択します。指定したフィールド名の集約関数プルダウンリストから適用する集約関数を選択します。
「COUNT(*)」を設定する場合は「2」の画面からのみ設定でき、集約関数タブ上では選択できません。
集約関数を取り消す
(2)の画面でフィールドを選択しての右クリックメニューから「集約関数」を経由して「なし」を選択します。
または集約関数タブのフィールドをクリックし、右クリックして表示されるメニューから「削除」をクリックします。
集約関数が設定されていてもそのフィールドがSELECT対象に含まれていない(フィールドがチェックされていない)場合はSELECT句にその項目は含まれません。
GROUP BY句にはSELECT対象のフィールドで集約関数が含まれていないフィールドが自動的に設定されます。
●テーブルの結合(リレーション)
SQLビルダーでは、リレーションを含んだSQL文を自動生成することができます。テーブル間でリレーションを設定するには、以下の手順で行います。
- (2)に、複数の対象テーブルを表示します。
- 対象テーブルのフィールド名をクリックしてドラッグを開始し、他の対象テーブルのフィールド名へリンクを連結します。
- 連結したリンクを右クリックして表示されるメニューの「リレーション種別」から種別をクリックします。
リレーションを削除するには、連結したリンクを右クリックして表示されるメニューから「リレーション削除」をクリックします。
●レコードの抽出(WHERE)
SQLビルダーでは、レコードの抽出条件を固定値と比較したりフローの中での動的な値と比較したりする設定を行うことができます。また、条件式を直接入力してSQL文に追加記述することができます。
固定値と比較する
- (2)のフィールドリストでフィールドをクリックし、右クリックして表示されるメニューから「条件の追加」をクリックします。
- 条件の編集ダイアログボックスで「固定値との比較」ラジオボタンをクリックします。
- 条件式をプルダウンリストから選択します。
- 固定値をテキストフィールドに入力します。
- 値を「'」で囲む場合は、「値を「'」で囲む」チェックボックスをオンにします。
(5)のSQL文に抽出条件が追加されます。(2)のフィールドリストに条件式が表示されます。
SQLパラメーターを使って実行時の動的な値の抽出条件を指定する
SQLビルダーで、任意の名前のパラメーターを定義し、抽出条件にするフィールド名に条件を追加する際にパラメーター名を指定することにより、パラメーターをWHERE句をSQL文の中に組み込みます。本コンポーネントの前にマッパーを配置し、定義したパラメーターにマッピングすることにより、実行時の動的な値を抽出条件にすることができます。
動的な値の抽出条件を指定するためには、以下の手順で行います。
- 最初に、(4)のパラメータータブで、任意の名前、データ型、初期値のパラメーターを定義します。
- (2)のフィールドリストでフィールドをクリックし、右クリックして表示されるメニューから「条件の追加」をクリックします。
- 条件の編集ダイアログボックスで「パラメーターとの比較」ラジオボタンをクリックします。
- 条件式をプルダウンリストから選択します。
- 定義したパラメーターが表示されるプルダウンリストから選択します。
- 値を「'」で囲む場合は、「値を「'」で囲む」チェックボックスをオンにします。
GoogleBigQueryGetコンポーネントの前にマッパーを配置し、マッピングウィンドウの出力側にあるパラメーターのフィールド名に値となるフィールドをマッピングします。
(5)のSQL文に抽出条件が追加されます。(2)のフィールドリストに条件式が表示されます。
任意の条件を指定する
任意の条件を指定するには、以下の2つの方法があります。以下の方法で操作すると、(5)のSQL文に抽出条件が追加されます。
条件の編集ダイアログボックスから
- (2)のフィールドリストでフィールドをクリックし、右クリックして表示されるメニューから「条件の追加」をクリックします。
- 条件の編集ダイアログボックスで「直接入力」ラジオボタンをクリックします。
- 条件式をテキストボックスに直接入力します。
(4)の画面から(条件タブ)
- 条件タブの「任意の条件を追加」をクリックします。
- 条件式をテキストボックスに直接入力します。
抽出条件を組み合わせる
いろいろな条件を組み合わせて抽出を行う場合、(4)の条件タブで論理演算子を指定することができます。条件フィールドの「関係」項目のプリダウンリストから「AND」または「OR」をクリックします。
抽出条件を編集する
指定した抽出条件を編集するには、条件タブのフィールドをダブルクリックします。または、フィールドをクリックし、右クリックして表示されるメニューから「条件の編集」をクリックします。
抽出条件を取り消す
条件タブのフィールドをクリックし、右クリックして表示されるメニューから「削除」をクリックします。
●SQLパラメーターを使って実行時に動的なSQL文を生成する
SQLビルダーのSQLパラメーターは、抽出条件(WHERE句)を設定する以外に、SQL文の中での任意の文字列を置き換えることができます。任意の名前のパラメーターを定義し、(5)で直接パラメーターを記述します。また、条件の編集ダイアログボックスで任意の条件を指定するときに記述することもできます。本コンポーネントの前にマッパーを配置し、定義したパラメーターにマッピングすることにより、実行時に動的なSQL文にすることができます。
動的なSQL文を指定するためには、以下の手順で行います。
- (4)のパラメータータブで、任意の名前、初期値で、データ型はStringのパラメーターを定義します。
- (5)で、置き換えたい文字列を使用する部分に「$パラメーターのフィールド名$」のようにフィールド名を$で囲んで記述します。
- GoogleBigQueryGetコンポーネントの前にマッパーを配置します。
- マッピングウィンドウの出力側にあるSQLパラメーターのフィールド名に置換文字列となるフィールドをマッピングします。
●パラメーターを編集する
(4)でフィールドを右クリックして表示されるメニューから「上に移動」「下に移動」「挿入」「削除」を操作します。
●自動生成したSQL文を直接編集する
(1)~(4)の指定で自動生成したSQL文が(5)に表示されます。(5)を直接編集すると、そのSQL文をそのままGoogleBigQueryに発行します。直接編集する際には、自動生成したSQL文と同期すると元に戻るため注意が必要です。同期設定については次項の「自動生成するSQL文表示のオプション」を参照してください。
●SQL文をテスト実行する
実際にGoogleBigQueryにSQL文を発行してテスト実行するには、以下の手順で行います。
- (5)の画面下部右側にある「SELECTテスト」をクリックします。
- パラメーターを定義している場合、パラメーターの値を指定するダイアログボックスで「初期値」項目にテスト用の値を設定して「OK」をクリックします。
正常終了の場合、実行結果がダイアログボックスに結果セットが表示されます。異常終了の場合、エラーメッセージダイアログボックスに表示されます。
結果セットの表示数を変更する
(5)の画面下部右側にある「テスト結果の行数」フィールドの行数を変更してから「SELECTテスト」をクリックします。初期値は100です。
●自動生成するSQL文表示のオプション
(5)の表示については、画面下部右側でオプションを指定することができます。
(5)のSQL文の編集について
SQLビルダーを使って指定したフィールドの選択、条件などのことをモデルといいます。「SQLを常に同期する」チェックボックスがオンの場合、(1)~(4)のモデルと(5)のSQL文が同期して自動生成された状態です。自動生成したSQL文を(5)で直接編集することができます。この場合、モデルを操作すると直接編集したSQL文が同期しないように、自動的に「SQLを常に同期する」チェックボックスがオフになります。直接編集をリセットした場合や再度操作したモデルからSQL文を自動生成する場合、「モデルをSQLに適用する」をクリックします。
オプション
- SQLを常に同期する
オンの場合、フィールドの選択、条件を指定するたびに自動生成します。
オフの場合、フィールドの選択、条件を指定しても自動生成しません。
- デフォルトスキーマを省略する
オンの場合、デフォルトスキーマを省略します。
オフの場合、デフォルトスキーマを記述します。
- エイリアスを使用する
オンの場合、エイリアスを記述します。
オフの場合、エイリアスを省略します。
- 名前を「"」で囲む
オンの場合、フィールド名を"(ダブルクォーテーション)で囲みます。
オフの場合、フィールド名を"(ダブルクォーテーション)で囲みません。
- SQLをインデントする
オンの場合、SQL文をインデントして表示します。
オフの場合、SQL文を1行で表示します。
- モデルをSQLに適用する
クリックしたとき、モデルからSQL文を自動生成します。直接編集していたSQL文は無効になります。
●注意事項
- SQL文の中に「$」や「?」という文字自身を使用したい場合は「$$」「??」のようにエスケープします。
- SQL文にマッパーで値を差し込んだ場合や、置換文字列を使用した場合はSQL実行のたびにパースが必要になり、処理に時間がかかる場合があります。SQLパラメーターは、WHERE句を指定する場合にのみ使用する方が高速です。
●GoogleBigQuery コネクション設定
| Allow Large Result Sets[AllowLargeResultSets] |
大きなデータセットの場合に、大きなデータセットをテンポラリーテーブルに格納するかしないか。 Default Value: true | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Auto Cache[AutoCache] |
AutoCache が設定されている場合、本製品 は、CacheLocation オプションで指定されているキャッシュにSELECT クエリの結果を自動的にキャッシュします。CacheLocation は、シンプルなファイルベースのキャッシュへのパスを定義します。 以下のセクションでは、AutoCache の仕組みと制限について説明します。
AutoCache の仕組みAutoCache セットでSELECT ステートメントを実行すると、本製品 はリモートデータにクエリを実行し結果を保持します。既存の行は上書きされます。つまり、SELECT ステートメントは、キャッシュのクエリではなくキャッシュの作成および更新に使用されます。 ノンクエリ要求(UPDATE/INSERT/DELETE ステートメントなど)は、リモートデータに対しても実行されます。これらのステートメントは、AutoCache の設定値に関係なく、キャッシュ内のデータは何も変更されません。 キャッシュされたデータをクエリするには、 #CACHE を テーブル名に追加します。次に例を示します。
SELECT * FROM [publicdata:samples.github_nested#CACHE] AutoCache を使用するタイミング軽量のキャッシュが必要なシナリオでは、AutoCache は設定を簡素化します。例えば、レポートを持続させるのに効果的です。Offline をtrue に設定すると、オフラインの状態でもレポートのローカルコピーにアクセスできます。 これらのプロパティを一緒に使用する例については、キャッシュ:ベストプラクティス を参照してください。 AutoCache の機能は、同じテーブル(1つまたは複数)の複数のレポートでより制限されます。AutoCache は、テーブルメタデータではなく結果セットのメタデータを持続するため、テーブルメタデータを先に取得する必要があります。CacheMetadata を使って、最初の接続で完全なデータモデルのメタデータを取得するか、CACHE ステートメント を使って、個々のテーブルのメタデータを取得できます。 AutoCache を使用しないタイミング以下のシナリオでは、次のような代替案を検討してください。
Default Value: false | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Cache Connection[CacheConnection] |
キャッシュデータベースは
CacheDriver
およびCacheConnection プロパティに基づいて決定されます。CacheConnection は、キャッシュデータベースへの接続に必要な接続プロパティを定義します。
Cache Driver=com.microsoft.sqlserver.jdbc.SQLServerDriver;Cache Connection='jdbc:sqlserver://localhost:7437;user=sa;password=123456;databaseName=Cache' | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Cache Driver[CacheDriver] |
JDBC ドライバーが用意されている任意のデータベースにキャッシュできます。本製品 はSQL Server、Derby およびJava DB、MySQL、 Oracle、およびSQLite に対してテスト済みです。 キャッシュデータベースは、CacheDriver およびCacheConnection プロパティに基づいて決定されます。
CacheDriver は、データのキャッシュに使用するJDBC ドライバークラスの名前です。次の例はSQL Server にキャッシュします。
Cache Driver=com.microsoft.sqlserver.jdbc.SQLServerDriver;Cache Connection='jdbc:sqlserver://localhost:7437;user=sa;password=123456;databaseName=Cache'ドライバーのJAR ファイルをクラスパスに指定する必要があることに留意してください。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Cache Location[CacheLocation] |
AutoCache は設定されているが、キャッシュの場所が指定されていない場合、デフォルトのCacheLocation は、Location 設定で指定されているディレクトリにあるキャッシュフォルダー になります。 CacheLocation は単純なファイルベースキャッシュです。ほかのデータベースにキャッシュするには、 CacheConnection および CacheDriver プロパティを参照してください。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Cache Metadata[CacheMetadata] |
cache.db ファイルは、CacheConnection で指定された場所に作成されます。これが設定されていない場合は、CacheLocation に作成されます。 Default Value: false | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Connect On Open[ConnectOnOpen] |
true に設定すると、接続が開かれたときにGoogle BigQuery への接続が作成されます。このプロパティは、さまざまなデータベースツールで[接続のテスト]機能を利用できるようにします。 この機能はNOOP コマンドとして作用します。Google BigQuery に接続できることを確認するために使用され、この初期接続からは何も維持されません。 このプロパティをfalse に設定すると、パフォーマンスが向上する場合があります(接続が開かれる回数に依存します)。 Default Value: true | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| データセットId[DatasetId] |
接続してテーブルを参照するデータセットのDatasetId。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Destination Table[DestinationTable] |
大きなクエリ結果を返すクエリの実行にはより長い時間がかかります。resultset が小さい場合でも、制限が追加されます:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Firewall Password[FirewallPassword] |
FirewallServer が指定されている場合は、FirewallUser およびFirewallPassword プロパティを使用して指定されたファイアウォールに接続し、認証を行います。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Firewall Port[FirewallPort] |
本製品 は、FirewallPort を、指定されたFirewallType に関連付けられたデフォルトのポートに設定します。 詳細については、FirewallType オプションの説明を参照してください。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Firewall Server[FirewallServer] |
このプロパティがドメイン名に設定されている場合は、DNS 要求が発行され、ドメイン名が対応するIP アドレスに変換されます。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Firewall Type[FirewallType] |
有効な値は次のとおりです。
Default Value: NONE Possible Values:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Firewall User[FirewallUser] |
FirewallServer が指定されている場合は、FirewallUser およびFirewallPassword プロパティを使用してファイアウォールに接続し、認証を行います。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Google Big Query Options[GoogleBigQueryOptions] |
Google BigQuery オプションのリスト:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| イニシエートOAuth[InitiateOAuth] |
次のオプションが利用可能です。
次のオプションが利用可能です。
Default Value: OFF Possible Values:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Location[Location] |
本製品 のスキーマファイル(テーブルとビューの場合は.rsd ファイル、ストアドプロシージャの場合は.rsb ファイル)を含むディレクトリへのパス。 Location プロパティは、定義をカスタマイズしたり(カラム名を変更する、カラムを無視するなど)、新しいテーブル、ビュー、またはストアドプロシージャでデータモデルを拡張する場合にのみ必要です。 アプリケーションで使用するスキーマファイルは、別のアセンブリと一緒に配布する必要があります。また、Location は、これらのスキーマファイルを含むフォルダーをポイントしている必要があります。 このフォルダーの場所は、実行可能ファイルの場所からの相対パスにすることができます。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Logfile[Logfile] |
ログファイルに記録される内容を細かく制御するには、Verbosity を参照してください。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Max Log File Size[MaxLogFileSize] |
ログファイルの最大バイトサイズ(例:10MB)を指定するstring。サイズリミットを超えると、新しいログが同じフォルダ内に作成され、日にちと時間が末尾に追加されます。デフォルトではリミットは設定されていません。100kB より小さい値を設定した場合、100kB がリミットとなります。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuthアクセストークン[OAuthAccessToken] |
OAuth を使用して接続するには、OAuthAccessToken プロパティが使用されます。認証プロセスにおいてOAuth サーバーからOAuthAccessToken が取得されます。このプロパティは、サーバーに依存するタイムアウトがあり、要求の間で再利用することができます。 アクセストークンは、ユーザー名とパスワードの代わりに使用されます。サーバー上で維持することで、認証情報が保護されます。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuthクライアントID[OAuthClientId] |
OAuth は、アプリケーションの登録を必要とします。登録するとき、コンシューマキーとも呼ばれるクライアントID、およびクライアントシークレットが提供されます。OAuth サーバーに接続するには、OAuthClientId およびOAuthClientSecret を指定する必要があります。 OAuth は、アプリケーションの登録を必要とします。登録するとき、コンシューマキーとも呼ばれるクライアントID、およびクライアントシークレットが提供されます。OAuth サーバーに接続するには、OAuthClientId およびOAuthClientSecret を指定する必要があります。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuthクライアントシークレット[OAuthClientSecret] |
OAuth は、アプリケーションの登録を必要とします。登録するとき、コンシューマシークレットとも呼ばれるクライアントID、およびクライアントシークレットが提供されます。OAuth サーバーに接続するには、OAuthClientId およびOAuthClientSecret を指定する必要があります。 OAuth は、アプリケーションの登録を必要とします。登録するとき、コンシューマシークレットとも呼ばれるクライアントID、およびクライアントシークレットが提供されます。OAuth サーバーに接続するには、OAuthClientId およびOAuthClientSecret を指定する必要があります。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuth JWT Cert[OAuthJWTCert] |
クライアント証明書のための証明書ストア名。 OAuthJWTCertType フィールドは、OAuthJWTCert により指定された証明書ストアの種類を指定します。 ストアがパスワードで保護されている場合は、OAuthJWTCertPassword でパスワードを指定します。 OAuthJWTCert は、 OAuthJWTCertSubject フィールドと共にクライアント証明書を指定するために使われます。 OAuthJWTCert に値がある場合で、OAuthJWTCertSubject が設定されている場合は、証明書の検索が始まります。 詳しくは、SSLClientCertSubject フィールドを参照してください。 証明書ストアの指定はプラットフォームに依存します。 Windows の共通のユーザとシステム証明書ストアの指定は以下のとおりです。
Javaでは、証明書ストアは通常、証明書および任意の秘密キーを含むファイルです。 証明書ストアの種類がPFXFile の場合は、このプロパティにファイル名を設定します。 PFXBlob の場合は、このプロパティをPFX ファイルのバイナリコンテンツ(例えば、PKCS12証明書ストア)に設定する必要があります。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuth JWT Cert Password[OAuthJWTCertPassword] |
証明書ストアでパスワードが必要である場合、このプロパティを使用してパスワードを指定し、証明書ストアにアクセスできます。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuth JWT Cert Subject[OAuthJWTCertSubject] |
証明書の件名は、証明書をロードするときにストア内の証明書を検索するために使用されます。 完全に一致するものが見つからない場合、ストアはプロパティの値を含む件名を検索します。 それでも一致するものが見つからない場合、プロパティは空白で設定され、証明書は選択されません。 "*" を設定すると、証明書ストアの1番目の証明書が選択されます。 証明書の件名は識別の名前フィールドおよび値のカンマ区切りのリストです。 例えば、"CN=www.server.com, OU=test, C=US, E=support@cdata.com"。共通のフィールドとその説明は以下のとおりです。
フィールド値にカンマが含まれている場合は、それを引用符で囲む必要があります。 Default Value: * | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuth JWT Cert Type[OAuthJWTCertType] |
このプロパティには次の値の一つを設定できます。
Possible Values:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuth JWT Issuer[OAuthJWTIssuer] |
Java Web Token の発行者です。通常は、OAuth アプリケーションのクライアントID またはE メールアドレスとなります。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuth JWT Subject[OAuthJWTSubject] |
アプリケーションからデリゲートアクセスの要求対象となるユーザーサブジェクトです。通常は、ユーザーのアカウント名またはE メールアドレスとなります。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuth Refresh Token[OAuthRefreshToken] |
OAuthRefreshToken プロパティは、OAuth 認証時にOAuthAccessToken のリフレッシュに使われます。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OAuth設定場所[OAuthSettingsLocation] |
InitiateOAuth にGETANDREFRESH またはREFRESH が設定されている場合、本製品 が設定ファイルにOAuth を保存するため、ユーザーが手動でOAuth 接続プロパティに接続する必要はありません。デフォルトOAuthSettingsLocation は、%AppData%\CData フォルダ内にある設定ファイルです。 InitiateOAuth にGETANDREFRESH またはREFRESH が設定されている場合、本製品 が設定ファイルにOAuth を保存するため、ユーザーが手動でOAuth 接続プロパティに接続する必要はありません。デフォルトOAuthSettingsLocation は、%AppData%\CData フォルダ内にある設定ファイルです。 Default Value: %APPDATA%\\CData\\GoogleBigQuery Data Provider\\OAuthSettings.txt | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Offline[Offline] |
Offline がTRUE に設定されている場合、すべてのクエリは、ライブデータソースではなくキャッシュに対して実行されます。このモードでは、INSERT、UPDATE、DELETE、CACHE などのクエリは許可されません。 Default Value: false | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Other[Other] |
Other プロパティは、データソース固有の接続パラメータで使用される名前と値のペアのセミコロン区切りリストです。 キャッシュの設定
統合およびフォーマット
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Page Size[PageSize] |
ページサイズは、Google BigQuery から、ページごとの戻りの結果数をコントロールできます。より大きなページサイズを設定することにより、一度のHTTP リクエストで返せるデータの量を増やすことができます。ただし、実行にはより長い時間がかかります。より小さなページサイズを設定することにより、すべてのデータを取得するのに必要なHTTP リクエスト数が増加します。ただし、タイムアウト切断が起こらないようにすることを推奨します。 Default Value: 100000 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Polling Interval[PollingInterval] |
Destination Table が設定されている場合、もしくはAllowLargeResultSets がtrue に設定されている場合のみ使用可能です。このプロパティは、クエリ結果が準備できているかを確認する間隔をどの長さにするかを決定します。非常に大きなクエリ結果や複雑なクエリは処理に時間がかかります。ポーリング感覚が短い場合には、クエリ状況を確認する不要な要求が送られる結果を引き起こします。 Default Value: 2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| プロジェクトId[ProjectId] |
接続してテーブルを参照するプロジェクトのProjectId。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Proxy Auth Scheme[ProxyAuthScheme] |
この値は、BASIC、DIGEST、NONE、NTLM、NEGOTIATE、PROPRIETARY のいずれかです。 Default Value: BASIC Possible Values:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Proxy Auto Detect[ProxyAutoDetect] |
これは、デフォルトのシステムプロキシ設定を使用するかどうかを示します。カスタムプロキシ設定を使用するには、ProxyAutoDetect をFALSE に設定します。これは他のプロキシ設定より優先されます。 Default Value: true | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Proxy Password[ProxyPassword] |
ProxyServer が指定されている場合は、ProxyUser およびProxyPassword プロパティを使用してファイアウォールに接続し、認証を行います。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Proxy Port[ProxyPort] |
詳細については、ProxyServer フィールドの説明を参照してください。 Default Value: 80 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Proxy Server[ProxyServer] |
このプロパティがドメイン名に設定されている場合は、DNS 要求が発行され、ドメイン名が対応するアドレスに変換されます。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Proxy SSL Type[ProxySSLType] |
この値は、AUTO、ALWAYS、NEVER、TUNNEL のいずれかです。 Default Value: AUTO Possible Values:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Proxy User[ProxyUser] |
ProxyServer が指定されている場合は、ProxyUser およびProxyPassword オプションを使用してファイアウォールに接続し、認証を行います。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Pseudo Columns[PseudoColumns] |
Entity Framework ではテーブルカラムでない疑似カラムに値を設定できないため、この設定はEntity Framework で特に便利です。 この接続設定の値は、"Table1=Column1, Table1=Column2, Table2=Column3" の形式です。 "*=*" のように"*" 文字を使用して、すべてのテーブルとすべてのカラムを含めることができます。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Query Cache[QueryCache] |
QueryCache を使用すると、クエリの結果をインメモリにキャッシュし、そのキャッシュを期限切れになるまで使用することができます。同じクエリまたは似たクエリ(下記参照)が頻繁に実行される場合は、QueryCache を設定することで、パフォーマンスを向上させることができます。インメモリクエリキャッシュは複数の接続で共有されます。したがって、複数の接続が使用される場合でもパフォーマンスには有利に働きます。 QueryCache のキャッシュマネージャーは、キャッシュにある結果をまったく同じクエリに対してのみ利用するのではなく、キャッシュされたクエリのデータの一部を表すクエリに対しても利用します。例えば、以下のクエリでは、クエリA の実行時に作成されたキャッシュが、クエリB とクエリC でも結果の取得に使用されます。
SELECT * from Account; // Query A SELECT * from Account WHERE Name LIKE '%John'; // Query B SELECT Id, Name from from Account LIMIT 10; // Query C QueryCache を0に設定すると、インメモリキャッシュは無効になります。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Query Passthrough[QueryPassthrough] |
このオプションは、クエリをGoogle BigQuery にas-is で渡します。 Default Value: false | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Readonly[Readonly] |
このプロパティがtrue に設定されている場合、本製品 はSELECT クエリのみ許可します。INSERT、UPDATE、DELETE、およびストアドプロシージャクエリではエラーが返されます。 Default Value: false | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| RTK[RTK] |
RTK プロパティは、ビルドにライセンスを供与するために使用されます。 このプロパティの設定方法については、付属のライセンスファイルを参照してください。このruntime key は、OEM ライセンスを購入した場合にのみ使用できます。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SSL Server Cert[SSLServerCert] |
TLS/SSL 接続を使用する場合は、このプロパティを使用して、サーバーが受け入れるTLS/SSL 証明書を指定できます。 コンピュータによって信頼されていない他の証明書はすべて拒否されます。 これは、完全なPEM 証明書、証明書を含むファイルへのパス、公開鍵、MD5 サムプリント、またはSHA1 サムプリントの形式を取ることができます。 これを指定しない場合は、任意の信頼された証明書が受け入れられます。 '*' を指定するとすべての証明書を受け付けます(セキュリティ懸念上、推奨されません)。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tables[Tables] |
これらのテーブルを複数のデータベースからリストすると、負荷がかかる可能性があります。接続文字列でテーブルのリストを提供すると、本製品 のパフォーマンスが向上します。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Temp Table Dataset[TempTableDataset] |
大きな結果セットを伴うクエリを実行している際にテンポラリーテーブルを保有するデータセットの名前。 Default Value: _CDataTempTableDataset | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Temp Table Expiration Time[TempTableExpirationTime] |
テンポラリーテーブルの期限が切れるまでの時間(秒単位)。テーブルの期限を切らない場合には0 に設定します。最小値は3600(1時間)です。 Default Value: 3600 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Timeout[Timeout] |
Timeout プロパティが0に設定されている場合は、操作がタイムアウトしません。処理が正しく完了するか、エラー状態になるまで実行されます。 Timeout の有効期限が切れても処理が完了していない場合は、本製品 は例外をスローします。 Default Value: 60 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Verbosity[Verbosity] |
このプロパティは、本製品 がLogfile に報告する詳細の量を決定します。1 から5 までのVerbosity レベルがサポートされています。以下で、これらについて説明します。
Default Value: 1 |
その他詳細タブのオプション名と値は、以下URL の「接続文字列オプション」を参照ください。
こちら